Bring the mental model from Scaled Dot-Product Attention & Transformer Layers; this page will reuse it instead of restarting from zero.
Attention & Transformers
SSM Hybrids: Fixed-State Sequence Models for Long Context
How Mamba-style state-space models and hybrids trade a growing KV cache for a fixed recurrent state, then use selectivity and local attention to recover useful memory.
Concept Structure
SSM Hybrids: Fixed-State Sequence Models for Long Context
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
4prerequisites
1next concepts
4related links
Learning map
SSM Hybrids: Fixed-State Sequence Models for Long ContextBeforeScaled Dot-Product Attention & Transformer LayersNow4/4 sections readyTryManipulate one control and predict the visible change.NextSwiGLU: Gated MLP Blocks in Transformers
Conceptual Bridge
What should feel connected as you move through this page.
How Mamba-style state-space models and hybrids trade a growing KV cache for a fixed recurrent state, then use selectivity and local attention to recover useful memory.
The next edge should feel earned: use the demo prediction here before following SwiGLU: Gated MLP Blocks in Transformers.
Test the linkManipulate one control and predict the visible change.Then continue to SwiGLU: Gated MLP Blocks in Transformers
01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
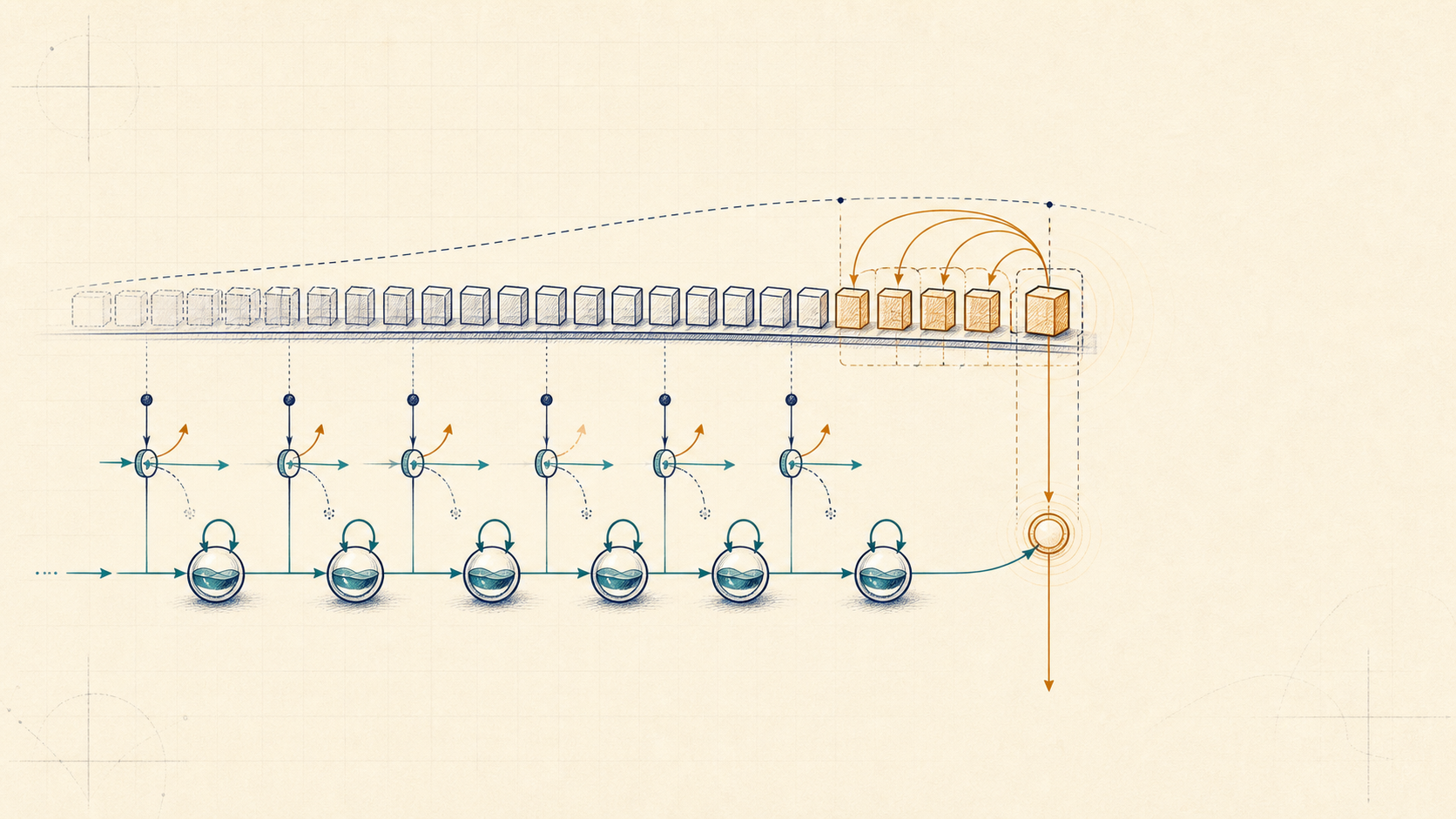
Attention keeps explicit memory. During autoregressive decoding, each layer stores keys and values for previous tokens. That is powerful because a later query can look back at a specific token, but the cache grows with context length.
State-space sequence models try a different bargain. Instead of keeping every past token as addressable memory, the model carries a fixed-size state forward:
The gain is concrete: a recurrent state can be updated in place as the prefix grows. The cost is also concrete: fixed state is compressed memory. If the state failed to preserve something, a later token cannot directly retrieve it as if it were still sitting in a KV cache.
That is why modern SSM pages should not start with "Mamba is faster." They should start with the memory question:
Can a model keep the useful part of the prefix in a fixed state, instead of keeping an explicit key and value for every token?
The old answer was often too blunt. A fixed linear recurrence uses the same update rule at every step, so noise and signal are treated similarly. Mamba-style selectivity changes the update from token to token. Important tokens can write strongly; distractors can barely update the state; long stretches can mostly copy the previous state forward.
Prediction checkpoint:
A marker token appears early, then many distractors arrive. Case A uses the same update strength on every token. Case B uses a large update on the marker and small updates on distractors. Which final state is more likely to still carry the marker?
The answer is not "recurrence always wins." The answer is: selectivity can preserve the marker in this toy setting because it changes when the state writes and when it copies. If every token gets the same gate, the advantage disappears. If the task needs exact random access to many old tokens, fixed state can be the bottleneck.
Hybrids exist because this tradeoff is real. Griffin/RecurrentGemma-style systems mix recurrence with local attention. Jamba-style systems interleave Transformer, Mamba, and MoE blocks. The recurring pattern is not "post-transformer means no transformer." It is: use recurrence for cheap long-range compressed state, use local or occasional attention where exact token-token interaction matters, and use MoE for capacity rather than memory.
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Equation 1x_t \in \mathbb R^{d_\text{in}}, \qquad h_t \in \mathbb R^N, \qquad y_t \in \mathbb R^{d_\tex...Equation 2h_t = \bar A h_{t-1} + \bar B x_t,
Start with a discrete linear time-invariant state-space model. Let
The recurrence is
where
This is the safe baseline. It is not yet Mamba. It is just a state updated through time.
With , unroll the recurrence:
Then
Define the kernel
Now the same model can be read as a convolution over the prefix:
That equivalence is exact for the fixed linear case. It is the first bridge: recurrence during streaming inference, kernel view over the sequence during training or analysis. Once , , or depend on the input, the model is no longer represented by one fixed time-invariant convolution kernel over the whole sequence.
Selectivity changes the story. Mamba-style selective SSMs let some parameters depend on the current token:
A simplified discretized update is
One common intuition is
In the scalar-gate intuition, changes the effective time scale. A large update emphasizes the current input. A small update mostly copies the previous state. Full selective SSM layers also use projections, channel structure, and token-dependent and ; the scalar gate is only the first mechanism to feel.
Now compare decode-time memory. For a global-attention Transformer layer with KV cache, a rough per-batch memory count is
Here is cached tokens, is layers, is key/value heads, and is head width.
For a recurrent state model, the state memory is closer to
or, in a Mamba-like expanded channel implementation,
The constants depend on architecture, but the sequence-length distinction is the point:
For a hybrid with local attention window , the recurrent part stays fixed-size, while local attention keeps only a bounded window if the implementation evicts or ignores out-of-window keys and values:
This does not mean hybrids always beat Transformers. It means they move the pressure. Recurrence compresses the long prefix; local attention handles exact nearby interactions; occasional global attention or Transformer layers add expressivity but can reintroduce cache growth.
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
This witness proves three small claims. First, a fixed linear SSM recurrence matches its convolution-kernel view. Second, token-dependent gates change which inputs write into state. Third, KV cache memory grows with context length while recurrent state memory does not.
import numpy as np
def fixed_recurrence(xs, A, B, C, D):
h = np.zeros((A.shape[0],))
ys = []
for x in xs:
h = A @ h + B @ x
ys.append(C @ h + D @ x)
return np.array(ys)
def kernel_view(xs, A, B, C, D):
ys = []
for t, x_t in enumerate(xs):
y = D @ x_t
for i in range(t + 1):
power = np.linalg.matrix_power(A, t - i)
y = y + C @ power @ B @ xs[i]
ys.append(y)
return np.array(ys)
def selective_scalar_copy(tokens, gates):
h = 0.0
states = []
for x_t, delta_t in zip(tokens, gates):
h = (1.0 - delta_t) * h + delta_t * x_t
states.append(h)
return np.array(states)
def kv_cache_mb(T, layers=32, batch=1, h_kv=8, d_head=128, bytes_per_scalar=2):
return batch * layers * 2 * T * h_kv * d_head * bytes_per_scalar / 1_000_000
def recurrent_state_mb(layers=32, batch=1, d_inner=4096, n_state=16, bytes_per_scalar=2):
return batch * layers * d_inner * n_state * bytes_per_scalar / 1_000_000
A = np.array([[0.8, 0.1], [0.0, 0.7]])
B = np.array([[1.0], [0.4]])
C = np.array([[0.6, -0.2]])
D = np.array([[0.05]])
xs = np.array([[1.0], [0.0], [0.5], [0.0]])
assert np.allclose(
fixed_recurrence(xs, A, B, C, D),
kernel_view(xs, A, B, C, D),
)
tokens = np.array([1.0, 0.0, 0.0, 0.0])
fixed_gates = np.array([0.35, 0.35, 0.35, 0.35])
selective_gates = np.array([0.9, 0.02, 0.02, 0.02])
fixed_final = selective_scalar_copy(tokens, fixed_gates)[-1]
selective_final = selective_scalar_copy(tokens, selective_gates)[-1]
print(round(fixed_final, 3), round(selective_final, 3))
print(round(kv_cache_mb(T=131_072), 1), round(recurrent_state_mb(), 1))
The scalar gate is not Mamba. It is a mechanism isolate: write strongly on marked information, copy through noise, and compare that with a fixed update rule.
The memory functions are not a latency benchmark. They only separate the terms that grow with from the terms that are fixed in sequence length.
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
Use the notebook sandbox as a toy selectivity test. A marked span appears among distractors. Before revealing the traces, predict whether the fixed-update LTI line, the selective-gate line, or a tie will preserve the marked tokens more cleanly.
After reveal, compare the per-token gates, hidden-state traces, clean marked-token copies, and false positives. Change the gate preset. If every token gets a similar gate, the selectivity advantage should shrink or vanish.
What to carry forward:
- Recurrence is compressed memory, not exact lookup.
- Selectivity changes when the state writes, copies, or forgets.
- Local attention remains valuable because fixed state cannot preserve everything.
- MoE adds sparse capacity; it does not by itself solve KV-cache growth.
- RAG and citations still matter when exact external evidence is required.
Canonical references: Gu and Dao, "Mamba: Linear-Time Sequence Modeling with Selective State Spaces", Dao and Gu, "Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality", AI21 Labs, "Jamba: A Hybrid Transformer-Mamba Language Model", and DeepMind, "RecurrentGemma: Moving Past Transformers for Efficient Open Language Models".
This page is in review because the demos are useful mechanism isolates, not full Mamba, Jamba, or Griffin implementations. The next publish pass should audit labels, code equivalence, and every systems claim against the source papers.
Live Concept Demo
Explore SSM Hybrids: Fixed-State Sequence Models for Long Context
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 4/5graduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what SSM Hybrids: Fixed-State Sequence Models for Long Context should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
How Mamba-style state-space models and hybrids trade a growing KV cache for a fixed recurrent state, then use selectivity and local attention to recover useful memory.
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change SSM Hybrids: Fixed-State Sequence Models for Long Context should make visible.
Visual Inquiry
Make the image answer a mathematical question
How Mamba-style state-space models and hybrids trade a growing KV cache for a fixed recurrent state, then use selectivity and local attention to recover useful memory.
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make SSM Hybrids: Fixed-State Sequence Models for Long Context easier to reason about before the page gives the answer.
Source Grounding
Canonical references for the mechanism on this page.
Grounds selective state spaces with input-dependent parameters, linear-time sequence processing, and fast autoregressive inference for the Mamba architecture.
Open sourceGrounds the structured state-space duality view connecting attention-like and SSM-like sequence computations.
Open sourceGrounds hybrid Transformer-Mamba-MoE architecture claims without making Mamba a universal replacement for attention.
Open sourceGrounds recurrence/local-attention hybrid language-model framing and the need to scope efficiency claims to concrete architectures.
Open sourceClaim Review
How Mamba-style state-space models and hybrids trade a growing KV cache for a fixed recurrent state, then use selectivity and local attention to recover useful memory.
Source IDs and witness objects are attached for review; they are not proof by themselves.
gu-2023-mamba, dao-2024-ssd, lieber-2024-jamba, botev-2024-recurrentgemma
Use equation, code, and demo objects to check whether the source support is operational.
Sources are attached for review: Gu/Dao ground selective SSMs and Mamba's architecture-specific linear-time/fast-inference claims; Dao/Gu ground SSM-attention duality; Jamba and RecurrentGemma ground hybrid recurrence/attention/MoE design patterns.
Sources: Mamba: Linear-Time Sequence Modeling with Selective State Spaces, Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, Jamba: A Hybrid Transformer-Mamba Language Model, RecurrentGemma: Moving Past Transformers for Efficient Open Language ModelsReview-only: this claim is not yet substantively audited. Do not generalize Mamba results to every SSM-like or hybrid system, and treat the local demo as a mechanism isolate rather than a production throughput proof.Attached source IDs and witness refs are review targets, not proof.Source support candidates
paper 2023Mamba: Linear-Time Sequence Modeling with Selective State SpacesGrounds selective state spaces with input-dependent parameters, linear-time sequence processing, and fast autoregressive inference for the Mamba architecture.
paper 2024Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space DualityGrounds the structured state-space duality view connecting attention-like and SSM-like sequence computations.
paper 2024Jamba: A Hybrid Transformer-Mamba Language ModelGrounds hybrid Transformer-Mamba-MoE architecture claims without making Mamba a universal replacement for attention.
paper 2024RecurrentGemma: Moving Past Transformers for Efficient Open Language ModelsGrounds recurrence/local-attention hybrid language-model framing and the need to scope efficiency claims to concrete architectures.
Practice Loop
Try the idea before it explains itself
How Mamba-style state-space models and hybrids trade a growing KV cache for a fixed recurrent state, then use selectivity and local attention to recover useful memory.
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in SSM Hybrids: Fixed-State Sequence Models for Long Context.
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptSSM Hybrids: Fixed-State Sequence Models for Long ContextAttention & Transformers
Code witness comparisonSSM Hybrids: Fixed-State Sequence Models for Long Context code witness 1assert np.allclose(Prediction before revealSSM Hybrids: Fixed-State Sequence Models for Long Context interactive demoManipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes SSM Hybrids: Fixed-State Sequence Models for Long Context click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
SSM Hybrids: Fixed-State Sequence Models for Long Context
Anchored question
What is the smallest example that makes SSM Hybrids: Fixed-State Sequence Models for Long Context click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:attention-transformers/ssm-hybrids.
No local draft saved.
- Source ids to inspect: gu-2023-mamba, dao-2024-ssd, lieber-2024-jamba, botev-2024-recurrentgemma
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - SSM Hybrids: Fixed-State Sequence Models for Long Context Object key: concept:attention-transformers/ssm-hybrids Context: Attention & Transformers Anchor id: concept/concept-notebook/attention-transformers/ssm-hybrids Open question: What is the smallest example that makes SSM Hybrids: Fixed-State Sequence Models for Long Context click without losing the math? Evidence to inspect: - Source ids to inspect: gu-2023-mamba, dao-2024-ssd, lieber-2024-jamba, botev-2024-recurrentgemma - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/attention-transformers/ssm-hybrids
concept:attention-transformers/ssm-hybrids