Bring the mental model from Scaled Dot-Product Attention & Transformer Layers; this page will reuse it instead of restarting from zero.
Attention & Transformers
Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization
How frontier LLMs stretch context windows: positional extrapolation (RoPE scaling) plus KV cache memory tricks (GQA, paging, quantization, compression).
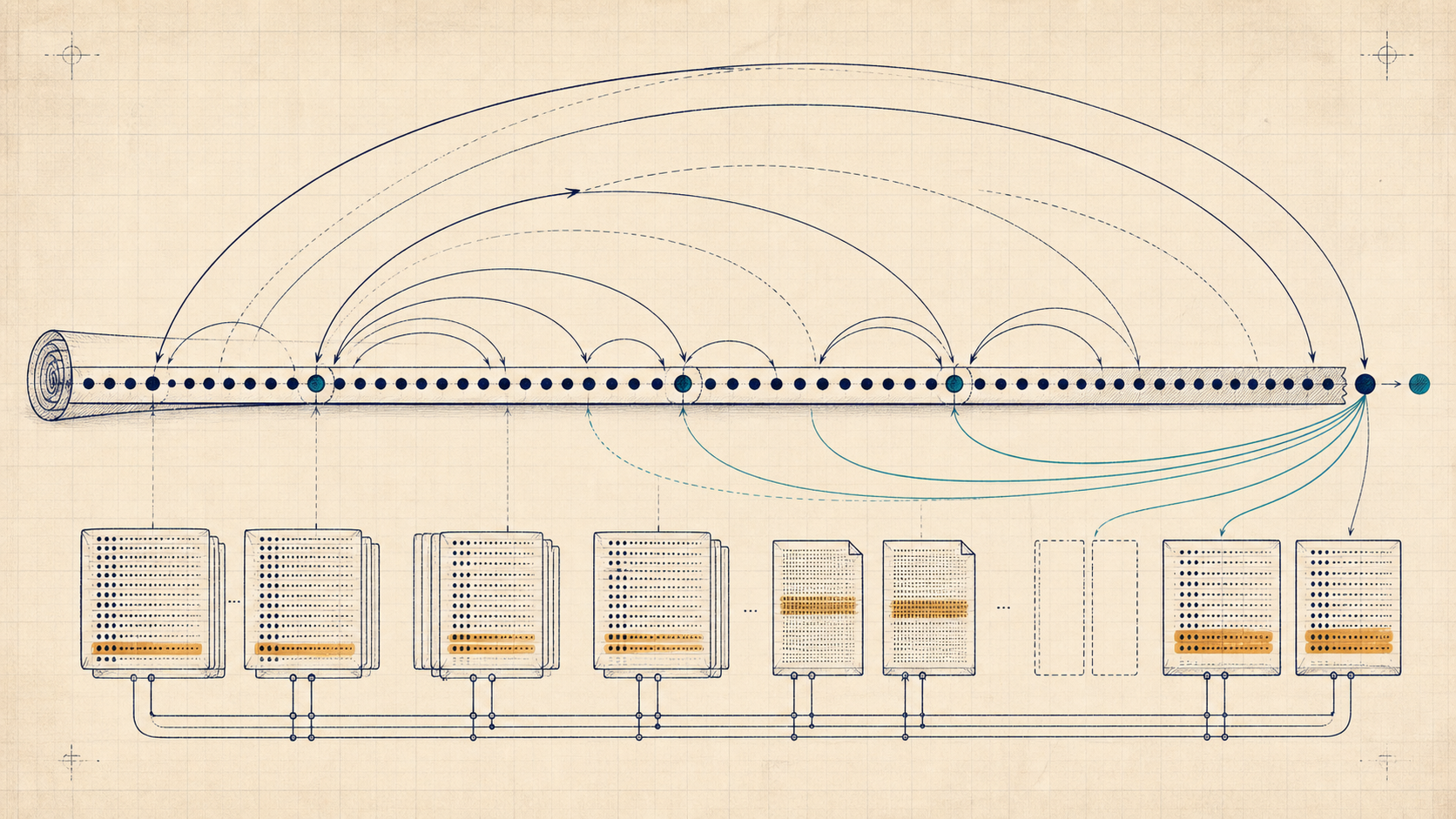
Concept Structure
Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
4prerequisites
2next concepts
2related links
Learning map
Long Context Engineering: RoPE Scaling, KV Compression & Memory OptimizationBeforeScaled Dot-Product Attention & Transformer LayersNow4/4 sections readyTryManipulate one control and predict the visible change.NextSSM Hybrids: Fixed-State Sequence Models for Long Context
Conceptual Bridge
What should feel connected as you move through this page.
How frontier LLMs stretch context windows: positional extrapolation (RoPE scaling) plus KV cache memory tricks (GQA, paging, quantization, compression).
The next edge should feel earned: use the demo prediction here before following SSM Hybrids: Fixed-State Sequence Models for Long Context.
Test the linkManipulate one control and predict the visible change.Then continue to SSM Hybrids: Fixed-State Sequence Models for Long Context
01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
Long context feels like "the model remembers more." In practice it's two different problems:
- Position extrapolation: the model must make sense of token positions it never saw during training (position is out-of-distribution).
- Memory and bandwidth: even if the model could use a million tokens, you still have to store and read the KV cache efficiently.
That's why long-context work is a two-front war. RoPE scaling methods (YaRN, LongRoPE, position interpolation) attack the "angle OOD" issue, while KV techniques (GQA/MQA, paging, quantization, eviction) attack the memory wall.
If you want a single production mental model: long-context inference is usually memory-bound, not compute-bound.
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Equation 1M_{ij} = \begin{cases} 0 \text{if } j \le i \text{ and } i-j \le W \\; -\infty \text{otherwis...Equation 2\mathrm{Attn}(Q,K,V)=\mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}+M\right)V.
Sliding window attention (reduce compute)
If each token attends only to the previous tokens, then attention compute is closer to instead of . One way to express this is with a mask:
and:
KV cache memory (the bottleneck at long )
Across a batch of sequences and layers, storing keys and values for tokens costs roughly:
This grows linearly in , and at long context it dominates the serving budget.
RoPE scaling (fix position OOD)
RoPE encodes position by rotating queries/keys. At positions far beyond training, those rotations can become out-of-distribution (especially for low-frequency dimensions). RoPE scaling methods effectively change the mapping so the model sees "less extreme" phases at long context, while preserving short-range detail.
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
import numpy as np
def kv_gb(T, L, Hkv, d_head, B=1, bytes_per_elem=2):
elems = B * L * T * Hkv * d_head * 2 # K and V
return elems * bytes_per_elem / 1e9
L, Hkv, d_head, B = 80, 8, 128, 8 # example: 80 layers, GQA with 8 KV heads, fp16
for T in [2048, 8192, 32768, 131072]:
print("T=", T, "KV~", round(kv_gb(T, L, Hkv, d_head, B), 2), "GB")
def attn_work(T, W, d):
# crude: per token ~ 2 * W * d multiply-adds (QK + weights*V)
return T * W * d * 2
T, d = 131072, 128
full = attn_work(T, T, d)
for W in [128, 512, 2048, T]:
print("window=", W, "relative attention work:", round(attn_work(T, W, d) / full, 6))
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
Use the demos to connect the "math knobs" to what serving systems actually feel:
- Sliding window reduces attention compute (but can hurt long-range retrieval).
- RoPE makes relative position usable at longer sequences.
- KV cache dashboards make the memory wall concrete.
Live Concept Demo
Explore Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 4/5graduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
How frontier LLMs stretch context windows: positional extrapolation (RoPE scaling) plus KV cache memory tricks (GQA, paging, quantization, compression).
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization should make visible.
Visual Inquiry
Make the image answer a mathematical question
How frontier LLMs stretch context windows: positional extrapolation (RoPE scaling) plus KV cache memory tricks (GQA, paging, quantization, compression).
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization easier to reason about before the page gives the answer.
Source Grounding
Canonical references for the mechanism on this page.
Direct PDF. Grounds RoPE as a rotary position mechanism whose query-key product can express relative offsets; not a RoPE-scaling recipe.
Open sourceDirect PDF. Grounds input-length extrapolation as a position-representation problem via ALiBi; this is a contrasting route, not a RoPE variant.
Open sourceDirect PDF. Grounds long-context serving feasibility as a KV-cache memory-management problem via paged KV-cache allocation.
Open sourceClaim Review
How frontier LLMs stretch context windows: positional extrapolation (RoPE scaling) plus KV cache memory tricks (GQA, paging, quantization, compression).
Claims without a substantive review badge still need exact source-support review.
su-2021-roformer, press-2021-alibi, kwon-2023-pagedattention
Use equation, code, and demo objects to check whether the source support is operational.
RoFormer grounds the rotary relative-position mechanism; ALiBi directly frames train-short/test-long length extrapolation as a position-representation problem; PagedAttention directly frames high-throughput serving as constrained by large, dynamic KV-cache memory.
Sources: RoFormer: Enhanced Transformer with Rotary Position Embedding, Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation, Efficient Memory Management for Large Language Model Serving with PagedAttentionChecks two long-context constraints, not every bottleneck; RoFormer is not a RoPE-scaling recipe, ALiBi is not RoPE, and local code/demo are toy witnesses, not production guarantees.A bounded review summary is present; still check caveats and exact source scope.RoFormer supports rotary relative-position mechanics; ALiBi supports train-short/test-long extrapolation as a position-representation issue; PagedAttention supports KV-cache memory as a serving bottleneck. Local code/demo are toy witnesses for KV sizing and phase constraints, not serving-system proof.
Reviewer: codex+oracle; reviewed 2026-05-07Source support candidates
paper 2021RoFormer: Enhanced Transformer with Rotary Position EmbeddingDirect PDF. Grounds RoPE as a rotary position mechanism whose query-key product can express relative offsets; not a RoPE-scaling recipe.
paper 2021Train Short, Test Long: Attention with Linear Biases Enables Input Length ExtrapolationDirect PDF. Grounds input-length extrapolation as a position-representation problem via ALiBi; this is a contrasting route, not a RoPE variant.
paper 2023Efficient Memory Management for Large Language Model Serving with PagedAttentionDirect PDF. Grounds long-context serving feasibility as a KV-cache memory-management problem via paged KV-cache allocation.
Practice Loop
Try the idea before it explains itself
How frontier LLMs stretch context windows: positional extrapolation (RoPE scaling) plus KV cache memory tricks (GQA, paging, quantization, compression).
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization.
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptLong Context Engineering: RoPE Scaling, KV Compression & Memory OptimizationAttention & Transformers
Code witness comparisonLong Context Engineering: RoPE Scaling, KV Compression & Memory Optimization code witne...elems = B * L * T * Hkv * d_head * 2 # K and VPrediction before revealLong Context Engineering: RoPE Scaling, KV Compression & Memory Optimization interactiv...Manipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization
Anchored question
What is the smallest example that makes Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:attention-transformers/long-context.
No local draft saved.
- Source ids to inspect: su-2021-roformer, press-2021-alibi, kwon-2023-pagedattention
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization Object key: concept:attention-transformers/long-context Context: Attention & Transformers Anchor id: concept/concept-notebook/attention-transformers/long-context Open question: What is the smallest example that makes Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization click without losing the math? Evidence to inspect: - Source ids to inspect: su-2021-roformer, press-2021-alibi, kwon-2023-pagedattention - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/attention-transformers/long-context
concept:attention-transformers/long-context