Bring the mental model from Maximum Likelihood; this page will reuse it instead of restarting from zero.
LLM Systems
Speculative Decoding: Lossless Multi-Token Generation
Draft several tokens with a fast model, score draft prefixes with the target model in parallel, then use modified rejection/residual sampling so the sampled distribution matches target-model decoding.
Concept Structure
Speculative Decoding: Lossless Multi-Token Generation
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
3prerequisites
1next concepts
2related links
Learning map
Speculative Decoding: Lossless Multi-Token GenerationBeforeMaximum LikelihoodNow4/4 sections readyTryManipulate one control and predict the visible change.NextLong Context Engineering: RoPE Scaling, KV Compression & Memory Optimization
Conceptual Bridge
What should feel connected as you move through this page.
Draft several tokens with a fast model, score draft prefixes with the target model in parallel, then use modified rejection/residual sampling so the sampled distribution matches target-model decoding.
The next edge should feel earned: use the demo prediction here before following Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization.
Test the linkManipulate one control and predict the visible change.Then continue to Long Context Engineering: RoPE Scaling, KV Compression & Memory Optimization
01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
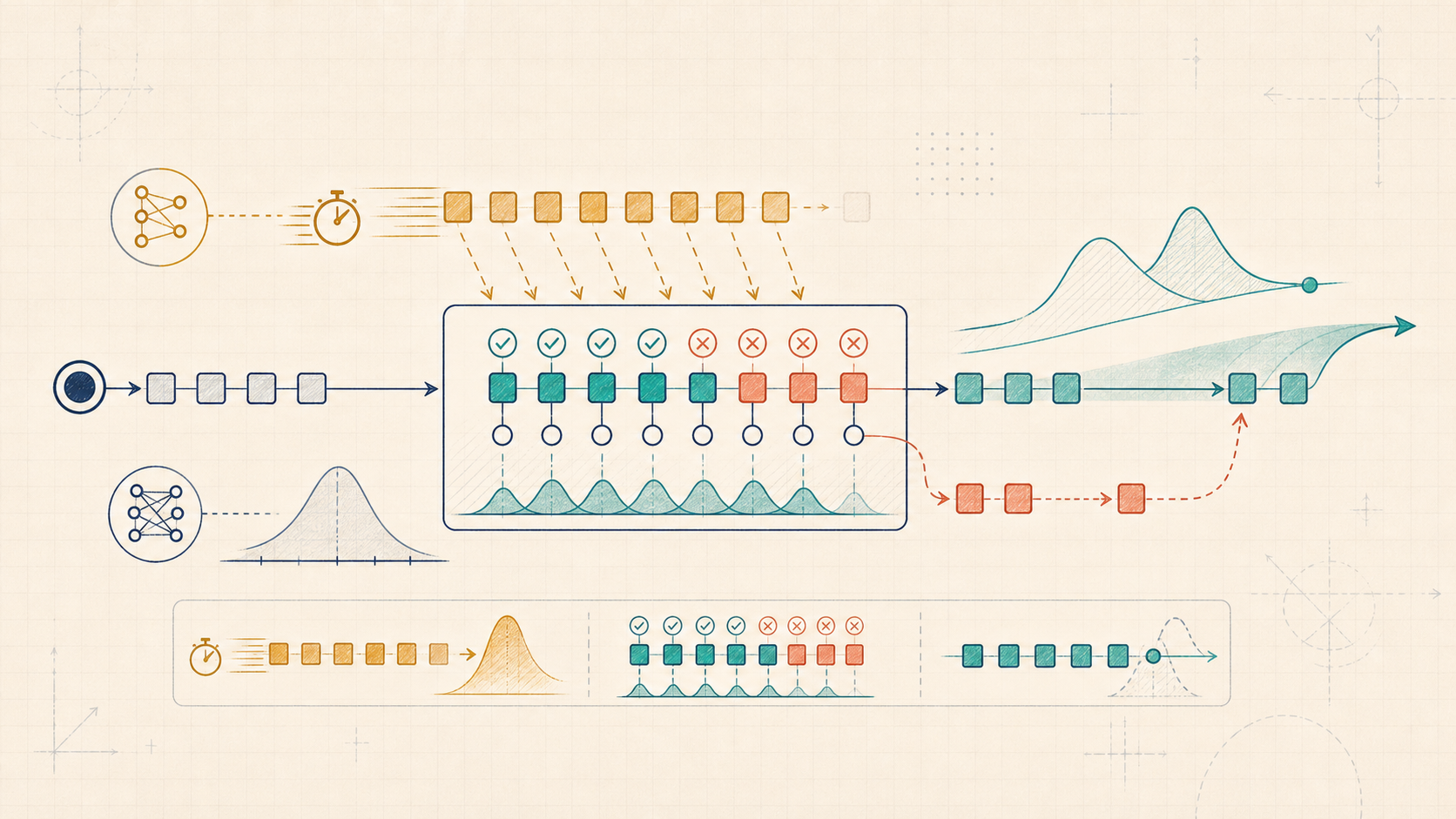
Autoregressive decoding is painfully sequential: one forward pass per token.
Speculative decoding gets around this by splitting work into two roles:
- a fast draft model proposes a chunk of next tokens,
- the expensive target model scores the prompt plus each draft prefix in parallel.
In the full algorithm, the target produces next-token distributions: one for the current prefix, one after each draft prefix, and an extra distribution that can supply a new target token if every draft token is accepted. If draft tokens pass the target/draft probability-ratio checks, you accept a prefix of the draft and "skip ahead" in the sequence. If one fails, you reject at the first failed token and repair that position with a residual sample so the target distribution is preserved. The key promise is that this is lossless: the final distribution of generated text is exactly what you would have sampled from the target model alone.
So the win is systems-level: fewer expensive sequential target steps, same output distribution.
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Equation 1\alpha_i = \min\!\left(1, \frac{p_i[x_i]}{q_i[x_i]}\right).Equation 2x_i \sim \mathrm{Normalize}\!\left(\max(0, p_i - q_i)\right).
Let be the draft distribution at position and be the target distribution. This page follows Leviathan et al.'s notation where is the target and is the draft; Chen et al. use the opposite symbols. If the draft proposes token , the acceptance probability is:
If a proposed token is rejected, you sample from a residual distribution that corrects for what the draft already "used up":
This rejection/residual mechanism is what makes the method lossless: accepted tokens come from but are filtered to match , and rejected positions are repaired to restore the exact distribution.
A rough intuition for speedup: if the draft is often right, you accept a long prefix of the proposed tokens, and the target model advances several tokens per verification step.
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
First check the one-token correction mechanism. Even though some samples come from the draft model, the accepted-or-repaired output should match the target distribution. Then simulate the accepted-prefix length that creates the latency upside.
import numpy as np
target_p = np.array([0.45, 0.30, 0.15, 0.10])
draft_q = np.array([0.30, 0.45, 0.20, 0.05])
rng = np.random.default_rng(0)
def residual_distribution(p, q):
repair_mass = np.maximum(0.0, p - q)
return repair_mass / repair_mass.sum()
def speculative_one_token(p, q):
draft = rng.choice(len(q), p=q)
accept_prob = min(1.0, p[draft] / q[draft])
if rng.random() < accept_prob:
return draft, True
repair = rng.choice(len(p), p=residual_distribution(p, q))
return repair, False
samples = np.zeros_like(target_p)
accepted = 0
for _ in range(200_000):
token, was_accepted = speculative_one_token(target_p, draft_q)
samples[token] += 1
accepted += int(was_accepted)
print("target distribution: ", np.round(target_p, 3))
print("speculative samples: ", np.round(samples / samples.sum(), 3))
print("draft-token acceptance:", round(accepted / samples.sum(), 3))
def expected_accepted(alpha, k):
# Expected length of consecutive acceptances (prefix), capped at k.
if alpha == 1.0:
return float(k)
return alpha * (1.0 - alpha**k) / (1.0 - alpha)
def simulate(alpha, k, trials=50000, seed=0):
rng = np.random.RandomState(seed)
total = 0
for _ in range(trials):
a = 0
for _ in range(k):
if rng.rand() < alpha:
a += 1
else:
break
total += a
return total / trials
for alpha in [0.3, 0.6, 0.85]:
for k in [2, 4, 8]:
theo = expected_accepted(alpha, k)
mc = simulate(alpha, k)
print(f"alpha={alpha:.2f} k={k:>2} E[accepted] theo={theo:.3f} mc={mc:.3f}")
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
Use the demo to see how acceptance probability, draft length, and distribution mismatch affect expected speedup, and why verification is "free" only if your target model can score the chunk efficiently.
Live Concept Demo
Explore Speculative Decoding: Lossless Multi-Token Generation
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 4/5undergraduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what Speculative Decoding: Lossless Multi-Token Generation should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
Draft several tokens with a fast model, score draft prefixes with the target model in parallel, then use modified rejection/residual sampling so the sampled distribution matches target-model decoding.
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change Speculative Decoding: Lossless Multi-Token Generation should make visible.
Visual Inquiry
Make the image answer a mathematical question
Draft several tokens with a fast model, score draft prefixes with the target model in parallel, then use modified rejection/residual sampling so the sampled distribution matches target-model decoding.
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make Speculative Decoding: Lossless Multi-Token Generation easier to reason about before the page gives the answer.
Source Grounding
Canonical references for the mechanism on this page.
Introduces speculative decoding as parallel draft-prefix scoring with modified rejection/residual sampling that preserves the target distribution.
Open sourceIndependently grounds K-token drafts, parallel target scoring, modified rejection sampling, residual repair, and measured large-model decoding speedups.
Open sourceClaim Review
Draft several tokens with a fast model, score draft prefixes with the target model in parallel, then use modified rejection/residual sampling so the sampled distribution matches target-model decoding.
Claims without a substantive review badge still need exact source-support review.
leviathan-2022-speculative-decoding, chen-2023-speculative-sampling
Use equation, code, and demo objects to check whether the source support is operational.
Leviathan defines gamma draft tokens from a faster approximation model, parallel target scoring of draft prefixes, accept/reject filtering, residual sampling from norm(max(0, p - q)), and proves target-distribution sampling. Chen independently describes K-token drafts, parallel target scoring, modified rejection/residual sampling, and preservation within hardware numerics.
Sources: Fast Inference from Transformers via Speculative Decoding, Accelerating Large Language Model Decoding with Speculative SamplingChecks lossless sampling under standardized sampling distributions; Chen qualifies the guarantee as within hardware numerics. Not a universal latency guarantee. Code is a toy finite-distribution/residual check plus prefix simulation; demo is a toy speedup witness, not proof.A bounded review summary is present; still check caveats and exact source scope.Leviathan 2022 supports gamma-token drafting, parallel target scoring of draft prefixes, accept/reject filtering, residual sampling from norm(max(0, p - q)), and a proof of target-distribution sampling. Chen 2023 independently supports K-token drafts, parallel scoring, modified rejection/residual sampling, and hardware-numerics-qualified preservation, with reversed p/q notation. Page math follows Leviathan; code is a toy residual/distribution plus prefix check, and demo is toy speedup only.
Reviewer: codex+oracle; reviewed 2026-05-07Source support candidates
paper 2022Fast Inference from Transformers via Speculative DecodingIntroduces speculative decoding as parallel draft-prefix scoring with modified rejection/residual sampling that preserves the target distribution.
paper 2023Accelerating Large Language Model Decoding with Speculative SamplingIndependently grounds K-token drafts, parallel target scoring, modified rejection sampling, residual repair, and measured large-model decoding speedups.
Practice Loop
Try the idea before it explains itself
Draft several tokens with a fast model, score draft prefixes with the target model in parallel, then use modified rejection/residual sampling so the sampled distribution matches target-model decoding.
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in Speculative Decoding: Lossless Multi-Token Generation.
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptSpeculative Decoding: Lossless Multi-Token GenerationLLM Systems
Code witness comparisonSpeculative Decoding: Lossless Multi-Token Generation code witness 1target_p = np.array([0.45, 0.30, 0.15, 0.10])Prediction before revealSpeculative Decoding: Lossless Multi-Token Generation interactive demoManipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes Speculative Decoding: Lossless Multi-Token Generation click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
Speculative Decoding: Lossless Multi-Token Generation
Anchored question
What is the smallest example that makes Speculative Decoding: Lossless Multi-Token Generation click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:llm-systems/speculative-decoding.
No local draft saved.
- Source ids to inspect: leviathan-2022-speculative-decoding, chen-2023-speculative-sampling
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - Speculative Decoding: Lossless Multi-Token Generation Object key: concept:llm-systems/speculative-decoding Context: LLM Systems Anchor id: concept/concept-notebook/llm-systems/speculative-decoding Open question: What is the smallest example that makes Speculative Decoding: Lossless Multi-Token Generation click without losing the math? Evidence to inspect: - Source ids to inspect: leviathan-2022-speculative-decoding, chen-2023-speculative-sampling - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/llm-systems/speculative-decoding
concept:llm-systems/speculative-decoding