Bring the mental model from Distributions; this page will reuse it instead of restarting from zero.
Probability
Maximum Likelihood
Maximum likelihood fits parameters by making the observed data most probable; for classifiers it becomes negative log-likelihood, cross-entropy, and a KL fit to the empirical distribution.
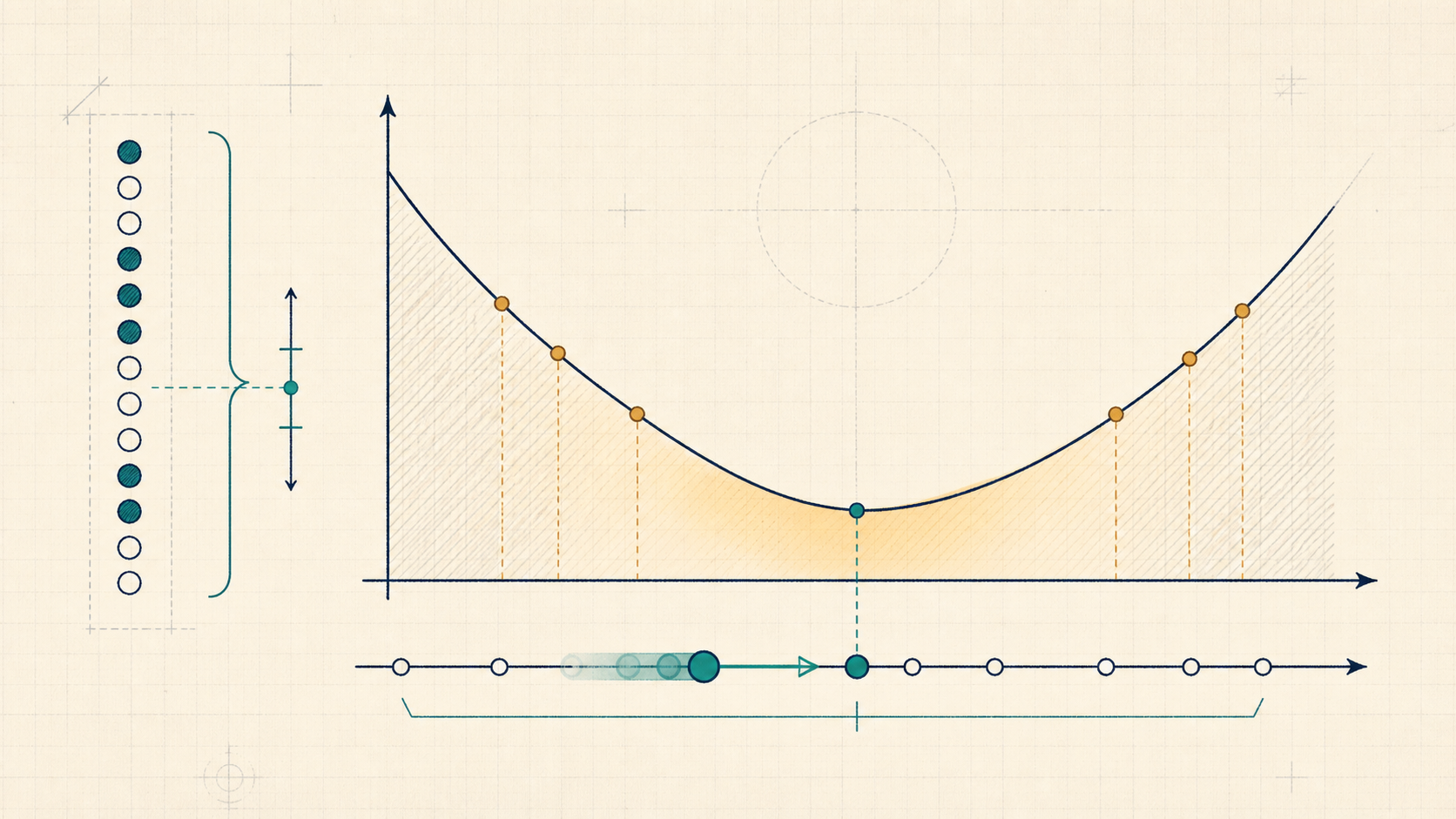
Concept Structure
Maximum Likelihood
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
2prerequisites
2next concepts
2related links
Learning map
Maximum LikelihoodBeforeDistributionsNow4/4 sections readyTryManipulate one control and predict the visible change.NextCross-Entropy
Conceptual Bridge
What should feel connected as you move through this page.
Maximum likelihood fits parameters by making the observed data most probable; for classifiers it becomes negative log-likelihood, cross-entropy, and a KL fit to the empirical distribution.
The next edge should feel earned: use the demo prediction here before following Cross-Entropy.
Test the linkManipulate one control and predict the visible change.Then continue to Cross-Entropy
01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
You observed data. Among all parameter settings your model allows, which one makes that exact data look least surprising?
Maximum likelihood answers by holding the observations fixed and moving the model parameters. A parameter setting is good when it assigns high probability, or high density for continuous data, to the values that actually appeared.
For a biased coin, if you saw 14 heads in 20 flips, the most likely head probability is not found by asking which coin is "fair." It is found by asking which value of makes the sequence with 14 heads and 6 tails most plausible. The answer is .
This same idea scales into deep learning. A classifier assigns probabilities to labels. A language model assigns probabilities to next tokens. Training by maximum likelihood means increasing the probability assigned to the observed labels or tokens. The negative log of that likelihood is the loss the optimizer actually minimizes.
The analogy has one important limit: likelihood is a score of parameters after the data are fixed. It is not, by itself, a posterior probability that a parameter is true. Bayesian inference adds a prior and normalizes over parameter values; maximum likelihood just finds the parameter value with the highest data score.
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Equation 1L(\theta)=\prod_{i=1}^n p_\theta(x_i).Equation 2\ell(\theta)=\log L(\theta)=\sum_{i=1}^n \log p_\theta(x_i).
Let be observed values treated as independent draws from a fixed parametric model family . The model family and parameter space are chosen before fitting; maximum likelihood only moves inside that family. All logarithms below are natural logarithms, so losses are measured in nats.
The likelihood is a function of the parameter:
The data values are fixed inside this expression. The variable being optimized is . Because products of many probabilities become tiny, we usually maximize log likelihood:
Equivalently, training minimizes average negative log-likelihood:
For a Bernoulli model with , parameter space , and , suppose observations are and are . For an ordered sequence,
and
If the data record only the count rather than the ordered sequence, the likelihood also has a binomial coefficient . That factor does not depend on , so it does not change the MLE.
On the open interval , the derivative is
When , setting it to zero gives
When or , there is no interior critical point. On the closed interval , the MLE is the boundary value or . On the open interval , the maximum is not attained; the likelihood only approaches its supremum at the boundary. The demo displays to avoid infinities from .
This is not a coincidence. The MLE for this Bernoulli family is the empirical frequency because the best one-parameter Bernoulli distribution matches the observed mass on and .
Now write the empirical distribution as
In this finite discrete setting, the average NLL is the cross-entropy from the empirical distribution to the model distribution:
And cross-entropy decomposes as
Here the empirical entropy is
and the forward KL mismatch is
The sums are over . Terms with contribute . If but , the NLL and KL are infinite.
Since does not depend on , maximum likelihood is equivalent here to minimizing the KL mismatch. If the model family cannot represent the empirical distribution exactly, MLE chooses the member of the family with the smallest mismatch inside that family.
The derivative of the average Bernoulli NLL with respect to is
If is produced by a logit with , then the chain rule gives
The demo reports this logit gradient. It is not the slope of the plotted curve with respect to .
For neural classifiers, is conditional on the input. The dataset objective is
For language models, is the next token at a position. The mechanism is the same: assign high probability to observed data, take logs, average, then use gradients to move parameters.
For continuous models, is a density rather than a probability mass. The likelihood scores density at the observed points; the probability of any exact point can be zero even while the likelihood density is high. Likelihood comparisons are meaningful within the same model and measurement units. The finite-sample objective is an empirical average of log density; a KL interpretation is clean when comparing expected NLL under a data-generating density to model densities with respect to the same base measure.
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
import numpy as np
# Observed Bernoulli data: 1=head/success, 0=tail/failure.
# Shape: y is (n,), theta is a scalar.
y = np.array([1, 1, 0, 1, 1, 0, 1, 0, 1, 1,
1, 0, 1, 1, 0, 1, 0, 1, 1, 1])
n = y.size
s = int(y.sum())
f = n - s
p_hat = s / n
def bernoulli_nll(theta):
theta = np.clip(theta, 1e-12, 1 - 1e-12)
return float(-(s * np.log(theta) + f * np.log(1 - theta)) / n)
def binary_entropy(p):
return float(sum(-value * np.log(value) for value in [p, 1 - p] if value > 0))
def bernoulli_kl(p, theta):
theta = np.clip(theta, 1e-12, 1 - 1e-12)
out = 0.0
if p > 0:
out += p * (np.log(p) - np.log(theta))
if p < 1:
out += (1 - p) * (np.log(1 - p) - np.log(1 - theta))
return float(out)
grid = np.linspace(0.01, 0.99, 99)
theta_grid_mle = grid[np.argmin([bernoulli_nll(t) for t in grid])]
# Closed-form MLE for Bernoulli.
theta_mle = p_hat
empirical_entropy = binary_entropy(p_hat)
kl_at_theta_04 = bernoulli_kl(p_hat, 0.4)
assert abs(bernoulli_nll(0.4) - (empirical_entropy + kl_at_theta_04)) < 1e-12
print("successes / n:", s, "/", n)
print("empirical p_hat:", round(p_hat, 3))
print("closed-form MLE:", round(theta_mle, 3))
print("grid MLE:", round(theta_grid_mle, 3))
print("NLL at theta=0.4:", round(bernoulli_nll(0.4), 3))
print("H(p_hat):", round(empirical_entropy, 3))
print("KL(p_hat || theta=0.4):", round(kl_at_theta_04, 3))
The code mirrors the math: the observations determine the empirical distribution, the likelihood is a function of , and the minimum average NLL occurs at .
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
Choose the observed number of successes, then move the model parameter . Before the likelihood curve appears, predict whether maximum likelihood should decrease , leave it where it is, or increase it.
For i.i.d. Bernoulli observations, the order of the sequence does not affect the likelihood; the count of successes is the sufficient statistic.
The reveal shows the average negative log-likelihood curve, the MLE line, the entropy baseline, the KL mismatch, and the logit gradient. Moving away from the empirical frequency increases the KL mismatch while the empirical entropy stays fixed.
Live Concept Demo
Explore Maximum Likelihood
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 3/5undergraduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what Maximum Likelihood should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
Maximum likelihood fits parameters by making the observed data most probable; for classifiers it becomes negative log-likelihood, cross-entropy, and a KL fit to the empirical distribution.
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change Maximum Likelihood should make visible.
Visual Inquiry
Make the image answer a mathematical question
Maximum likelihood fits parameters by making the observed data most probable; for classifiers it becomes negative log-likelihood, cross-entropy, and a KL fit to the empirical distribution.
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make Maximum Likelihood easier to reason about before the page gives the answer.
Source Grounding
Canonical references for the mechanism on this page.
Grounds maximum likelihood as the standard objective behind many supervised and generative models.
Open sourceClaim Review
Maximum likelihood fits parameters by making the observed data most probable; for classifiers it becomes negative log-likelihood, cross-entropy, and a KL fit to the empirical distribution.
Claims without a substantive review badge still need exact source-support review.
goodfellow-2016-deep-learning
Use equation, code, and demo objects to check whether the source support is operational.
Goodfellow et al. present maximum likelihood in log space as a sum over examples and connect negative log likelihood to the supervised-learning objective used for probabilistic models.
Sources: Deep LearningThis checks the likelihood objective, not a Bayesian posterior interpretation or a guarantee that the model family can represent the data-generating distribution.A bounded review summary is present; still check caveats and exact source scope.Checked Goodfellow et al. chapters 5.5 and 5.6: section 5.5 defines theta_ML as argmax over theta of p_model(X;theta), decomposes i.i.d. data into a product over examples, then uses logs to turn the product into sum_i log p_model(x_i;theta). It also frames training as minimizing -E_data log p_model, NLL, or cross-entropy. Section 5.6 contrasts ML point estimates with Bayesian posterior distributions over theta.
Reviewer: codex+oracle; reviewed 2026-05-06Practice Loop
Try the idea before it explains itself
Maximum likelihood fits parameters by making the observed data most probable; for classifiers it becomes negative log-likelihood, cross-entropy, and a KL fit to the empirical distribution.
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in Maximum Likelihood.
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptMaximum LikelihoodProbability
Code witness comparisonMaximum Likelihood code witness 1assert abs(bernoulli_nll(0.4) - (empirical_entropy + kl_at_theta_04)) < 1e-12Prediction before revealMaximum Likelihood interactive demoManipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes Maximum Likelihood click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
Maximum Likelihood
Anchored question
What is the smallest example that makes Maximum Likelihood click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:probability/maximum-likelihood.
No local draft saved.
- Source ids to inspect: goodfellow-2016-deep-learning
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - Maximum Likelihood Object key: concept:probability/maximum-likelihood Context: Probability Anchor id: concept/concept-notebook/probability/maximum-likelihood Open question: What is the smallest example that makes Maximum Likelihood click without losing the math? Evidence to inspect: - Source ids to inspect: goodfellow-2016-deep-learning - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/probability/maximum-likelihood
concept:probability/maximum-likelihood