This Information Theory concept is the current object: keep the same invariant visible across Intuition, Math, Code, Interactive Demo.
Information Theory
KL Divergence (Relative Entropy)
KL divergence is a directional expected log-probability mismatch between distributions; it explains cross-entropy training, variational inference, and KL-regularized alignment.
Concept Structure
KL Divergence (Relative Entropy)
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
2prerequisites
3next concepts
2related links
Learner Contract
What this page should let you do.
2 prerequisites listed; refresh them before leaning on the math or code.
Explain the mechanism, trace the main notation, and test one prediction in the live demo.
Read the intuition before the notation; the math should name a mechanism you already felt.
Follow this edge after making one prediction here; the next page should reuse the result, not restart the route.
Test the linkManipulate one control and predict the visible change.Then continue to Variational Autoencoders
Claim/source review status
Substantive review recorded
1/1 claims have bounded review metadata; still check caveats and source scope.Metadata-derived; review may be AI-assisted. Not a human certification.01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
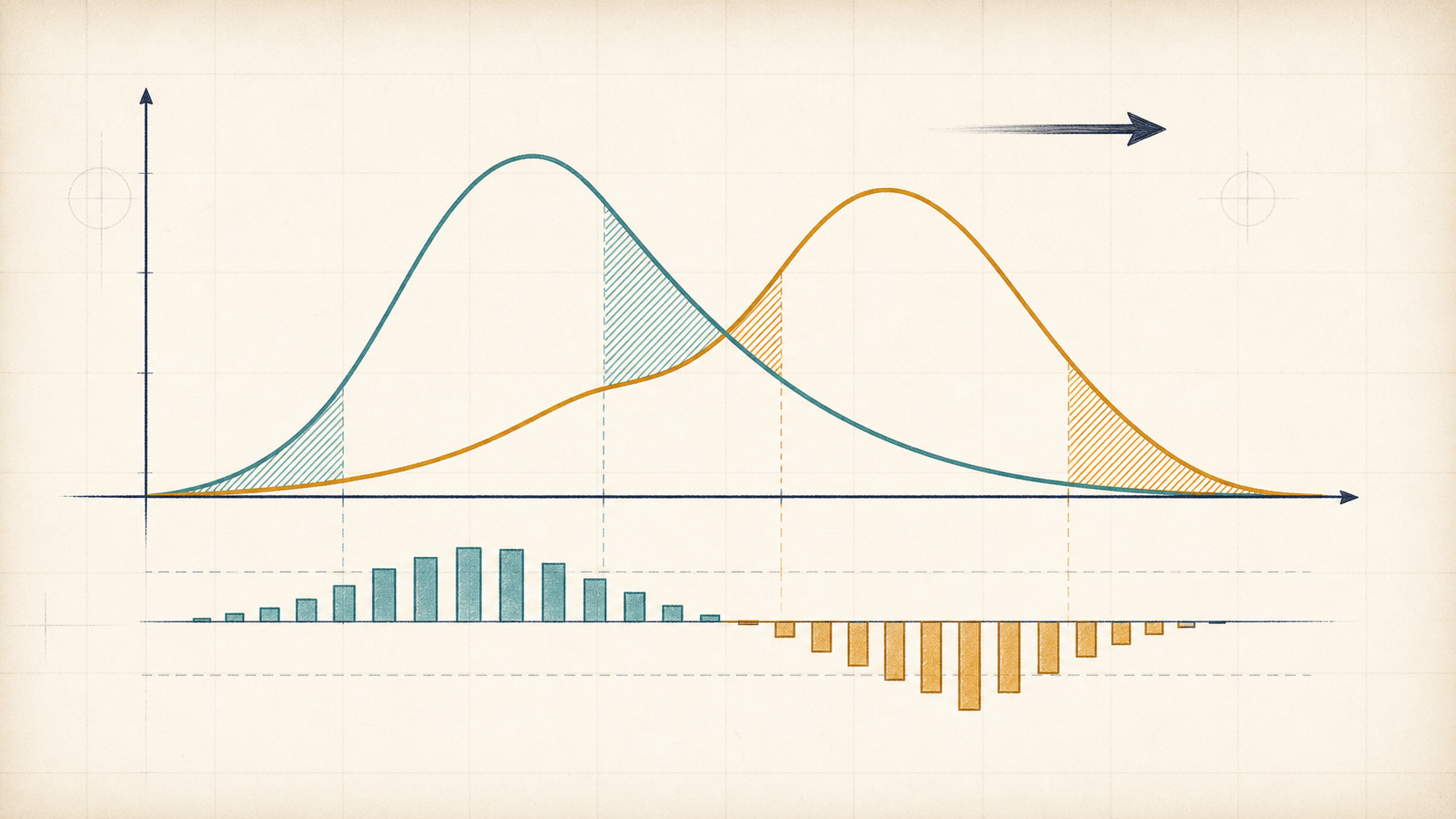
You have two distributions over the same outcomes. Distribution is the one you use for averaging, and distribution is the one whose probabilities you are testing. How much worse are the log-probabilities from on outcomes drawn from ?
KL divergence answers that directional question. It is not a symmetric distance between two shapes. It is an expected regret:
If says an event happens and assigns it tiny probability, the regret is large. If says an event never happens, that event does not directly matter for because it is never sampled under the averaging distribution.
This direction is why KL appears in several different guises:
- In maximum likelihood and cross-entropy, the data distribution is the averaging distribution, so missing a data mode is expensive.
- In KL-regularized alignment, the averaging distribution is often the new policy and the second distribution is a reference policy, so putting new-policy mass where the reference has little mass is expensive.
- In variational inference, with a restricted approximation family, choosing versus changes whether an approximation tends to seek one mode or cover many modes.
The extra-code-length analogy is useful: if samples really come from , but your code was optimized for , KL is the expected extra number of nats you spend per sample.
The letters are local. In supervised learning below, is usually the data or target distribution and is the model distribution. In a policy penalty such as , the first distribution is the new policy and the second distribution is the reference. The invariant idea is the direction of the expectation.
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Let and be probability distributions on the same finite or countable outcome space . The KL divergence from to is
Equivalently,
All logarithms here are natural logs, so the units are nats. Terms with contribute . If and , then . That support condition is not a technical footnote; it is the source of the "missing data mode" failure.
KL is nonnegative:
with equality exactly when as distributions, up to events with probability zero.
One quick way to see the nonnegativity is to let for outcomes where . Since is concave,
But , so . Multiplying by gives . This is why individual signed terms can be negative while the total divergence is never negative.
KL is generally asymmetric:
The asymmetry comes from the expectation. In , samples are drawn from . In , samples are drawn from . Changing the averaging distribution changes which mistakes are visited often.
The cross-entropy identity is
Here
and
The identity is just the pointwise equality
averaged under . If is fixed, minimizing cross-entropy over is the same as minimizing , because does not depend on the model. This is the clean finite-discrete version of the maximum-likelihood bridge: empirical data define , the model supplies , and training punishes low probability on observed outcomes.
For continuous variables with densities and relative to the same base measure,
Density values are not probabilities by themselves, and the common-reference-measure assumption matters. The practical lesson remains the same: KL compares log density ratios under one chosen averaging distribution.
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
import math
import numpy as np
def check_distribution(v):
v = np.asarray(v, dtype=float)
assert np.all(v >= 0)
assert abs(v.sum() - 1.0) < 1e-12
return v
def entropy(p):
p = check_distribution(p)
return float(sum(-px * math.log(px) for px in p if px > 0))
def cross_entropy(p, q):
p = check_distribution(p)
q = check_distribution(q)
assert p.shape == q.shape
if np.any((p > 0) & (q == 0)):
return math.inf
return float(sum(-px * math.log(qx) for px, qx in zip(p, q) if px > 0))
def kl(p, q):
p = check_distribution(p)
q = check_distribution(q)
assert p.shape == q.shape
if np.any((p > 0) & (q == 0)):
return math.inf
return float(sum(px * (math.log(px) - math.log(qx)) for px, qx in zip(p, q) if px > 0))
# Shapes: p and q are length-K categorical distributions.
# Supervised reading: p=data/target, q=model.
# Policy-regularization reading for KL(q||p): q=new policy, p=reference.
p = [0.55, 0.25, 0.15, 0.05]
q = [0.80, 0.15, 0.04, 0.01]
h_p = entropy(p)
h_pq = cross_entropy(p, q)
kl_pq = kl(p, q)
kl_qp = kl(q, p)
assert abs(h_pq - (h_p + kl_pq)) < 1e-12
print("KL(p || q):", round(kl_pq, 4))
print("KL(q || p):", round(kl_qp, 4))
print("H(p,q):", round(h_pq, 4))
print("H(p)+KL(p||q):", round(h_p + kl_pq, 4))
The code keeps the support behavior explicit: if assigns zero probability to an event that can sample, forward KL is infinite.
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
Use the presets or sliders to change while stays fixed. Before the KL totals appear, predict whether , , or neither direction should dominate.
The top bars compare the two distributions. After the reveal, the contribution rows show the signed per-outcome terms for and . Individual terms can be negative, but the total KL is nonnegative.
Missing a data mode makes spike because samples that mode and scores it poorly. Putting extra mass where the reference distribution is small makes spike because now samples from places the reference considers unlikely.
The sliders keep every weight positive, so the browser demo shows near-misses rather than exact infinities. The exact support-failure case is handled in the math definition and code above.
Live Concept Demo
Explore KL Divergence (Relative Entropy)
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 3/5undergraduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what KL Divergence (Relative Entropy) should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
KL divergence is a directional expected log-probability mismatch between distributions; it explains cross-entropy training, variational inference, and KL-regularized alignment.
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change KL Divergence (Relative Entropy) should make visible.
Visual Inquiry
Make the image answer a mathematical question
KL divergence is a directional expected log-probability mismatch between distributions; it explains cross-entropy training, variational inference, and KL-regularized alignment.
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make KL Divergence (Relative Entropy) easier to reason about before the page gives the answer.
Source Grounding
Canonical references for the mechanism on this page.
Chapter 3 grounds KL divergence, cross-entropy, and information-theoretic notation used in deep learning.
Open sourceClaim Review
KL divergence is a directional expected log-probability mismatch between distributions; it explains cross-entropy training, variational inference, and KL-regularized alignment.
Claims without a substantive review badge still need exact source-support review.
goodfellow-2016-deep-learning
Use equation, code, and demo objects to check whether the source support is operational.
Goodfellow et al. define KL divergence as relative entropy with an expected log-ratio form, relate it to cross-entropy, and use the same probability-information notation for deep learning objectives.
Sources: Deep LearningReviewed finite/countable same-space distributions and Ch3 cross-entropy identity with first distribution fixed. Demo keeps q positive, showing near-misses, not infinite-KL failures. Not measure theory, continuous edge cases, optimization guarantees, VI, or KL alignment uses.A bounded review summary is present; still check caveats and exact source scope.Checked Goodfellow Ch.3: KL is E_{x~P}[log(P/Q)], nonnegative, generally asymmetric, and cross-entropy is H(P,Q)=H(P)+D_KL(P||Q)=-E_P log Q. With P fixed, H(P) is constant, so cross-entropy differs from forward KL by fixed target entropy. Local math/code/demo match finite/countable p-weighted log-ratio, support rules, directional terms, nonnegative totals, and H(p,q)=H(p)+KL(p||q).
Reviewer: codex+oracle; reviewed 2026-05-07Practice Loop
Try the idea before it explains itself
KL divergence is a directional expected log-probability mismatch between distributions; it explains cross-entropy training, variational inference, and KL-regularized alignment.
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in KL Divergence (Relative Entropy).
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptKL Divergence (Relative Entropy)Information Theory
Code witness comparisonKL Divergence (Relative Entropy) code witness 1assert np.all(v >= 0)Prediction before revealKL Divergence (Relative Entropy) interactive demoManipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes KL Divergence (Relative Entropy) click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
KL Divergence (Relative Entropy)
Anchored question
What is the smallest example that makes KL Divergence (Relative Entropy) click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:information-theory/kl-divergence.
No local draft saved.
- Source ids to inspect: goodfellow-2016-deep-learning
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - KL Divergence (Relative Entropy) Object key: concept:information-theory/kl-divergence Context: Information Theory Anchor id: concept/concept-notebook/information-theory/kl-divergence Open question: What is the smallest example that makes KL Divergence (Relative Entropy) click without losing the math? Evidence to inspect: - Source ids to inspect: goodfellow-2016-deep-learning - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/information-theory/kl-divergence
concept:information-theory/kl-divergence