Bring the mental model from Maximum Likelihood; this page will reuse it instead of restarting from zero.
Generative Models
Variational Autoencoders
A latent-variable model trained by maximizing an evidence lower bound; the gap is KL(q_phi(z|x) || p_theta(z|x)), so the encoder is learned inference rather than just compression.
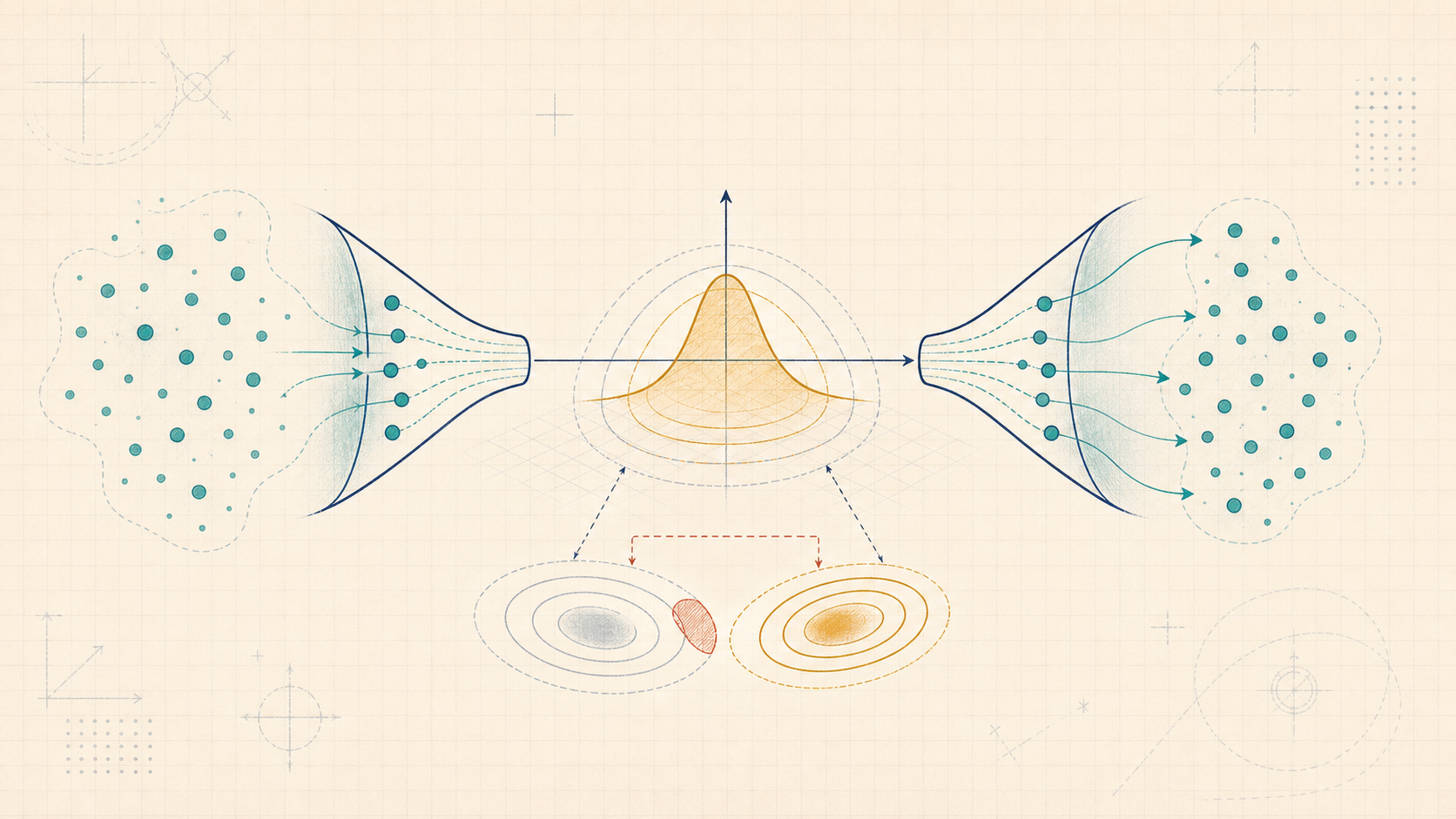
Concept Structure
Variational Autoencoders
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
3prerequisites
2next concepts
1related links
Learning map
Variational AutoencodersBeforeMaximum LikelihoodNow4/4 sections readyTryManipulate one control and predict the visible change.NextNormalizing Flows: Tractable Density via Invertible Transforms
Conceptual Bridge
What should feel connected as you move through this page.
A latent-variable model trained by maximizing an evidence lower bound; the gap is KL(q_phi(z|x) || p_theta(z|x)), so the encoder is learned inference rather than just compression.
The next edge should feel earned: use the demo prediction here before following Normalizing Flows: Tractable Density via Invertible Transforms.
Test the linkManipulate one control and predict the visible change.Then continue to Normalizing Flows: Tractable Density via Invertible Transforms
01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
Maximum likelihood asks for a model that assigns high log probability to the observed data:
A variational autoencoder is a maximum-likelihood model with a hidden cause. It imagines that each observation was produced from an unobserved latent variable :
Training would be easy if we could compute the marginal likelihood
The problem is that this integral is usually hard for neural decoders. Bayesian inference tells us what we would like to use:
But that posterior contains the same hard evidence term . The VAE move is to learn an encoder
that acts as a tractable approximate posterior.
The central mechanism is not "an autoencoder with noise." It is: replace the intractable posterior with a learned distribution , then optimize a lower bound whose looseness is exactly a KL divergence from to the true posterior.
That is why VAEs sit at the intersection of maximum likelihood, Bayesian inference, and KL divergence.
Two natural next moves branch from this page. Normalizing flows ask what changes when the latent transformation is invertible and likelihood stays exact. Diffusion asks what changes when generation is learned as a gradual denoising process rather than as one sampled latent code.
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Equation 1p_\theta(x,z)=p(z)p_\theta(x\mid z); p_\theta(x)=\int p_\theta(x,z)\,dz; p_\theta(z\mid x)=\f...Equation 2\log p_\theta(x) = \mathcal L(\theta,\phi;x) + \mathrm{KL}\!\left(q_\phi(z\mid x)\,\|\,p_\the...
Latent variable likelihood
For one observed datapoint , assume a prior and a decoder likelihood . The latent-variable model, marginal likelihood, and true posterior are
The evidence appears in the denominator, so exact posterior inference and exact likelihood training are tied to the same difficult integral. The claim-bearing VAE move is summarized by
The first line says the ELBO gap is exactly the KL from the learned encoder to the true posterior. The second line separates reconstruction likelihood from prior pressure. The third line keeps randomness in external noise , so gradients of sampled reconstruction terms can flow through into the encoder outputs.
The ELBO identity
Let be any approximate posterior whose support is compatible with the true posterior. To keep the equations readable, write for and for expectation under that distribution:
Using Bayes' rule and rearranging gives the exact identity
Here is the ELBO and is the inference gap. Let denote the true posterior . Then the gap is
Equivalently,
The ELBO term is
The gap can also be read by subtraction:
KL is nonnegative, so
Maximizing the ELBO improves this lower bound. The bound is tight exactly when the encoder distribution equals the true posterior, up to probability-zero events.
Reconstruction likelihood plus prior KL
Because
the ELBO can be rewritten as
The first term is a reconstruction log likelihood, not generically a pixel distance. The second term keeps the encoder's posterior close to the prior used for generation. At generation time we sample , not for a training example, so the prior match is load-bearing.
Reconstruction likelihood is not always MSE
The reconstruction term is
It becomes a familiar loss only after choosing a decoder distribution. With a fixed-variance Gaussian decoder centered at , the negative log likelihood is a scaled squared error plus a constant. So MSE appears as a Gaussian negative log likelihood only after that modeling choice.
If is binary and
then the negative reconstruction log likelihood is binary cross-entropy.
Reparameterization trick
For a diagonal Gaussian encoder, the network outputs and . We sample with external noise:
This keeps the randomness in and makes the sample differentiable with respect to the encoder outputs and .
Beta-VAE objective
A beta-VAE changes the training objective to
When , this is the standard VAE ELBO. When , it is a modified objective rather than the original ELBO. For , it remains a lower bound because it subtracts extra nonnegative KL penalty, but it is no longer the standard maximum-likelihood ELBO. For , it is generally not guaranteed to lower-bound .
Larger puts more pressure on to carry less information and stay close to the prior. This can encourage more factor-like representations in some settings, but it does not guarantee disentanglement. If the pressure is too strong, the encoder may approach , so carries little information about .
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
This scalar linear-Gaussian example is small enough that we can compute the exact marginal likelihood, exact posterior, ELBO, and inference gap, then check a one-sample reparameterized reconstruction gradient by finite differences.
import math
def log_norm(x, mean, var):
return -0.5 * (math.log(2 * math.pi * var) + (x - mean) ** 2 / var)
def kl_norm(mu0, var0, mu1, var1):
return 0.5 * (var0 / var1 + (mu1 - mu0) ** 2 / var1 - 1 + math.log(var1 / var0))
x, w, b, sigma_x = 1.5, 1.2, -0.1, 0.3 # z~N(0,1), x|z~N(wz+b,sigma_x^2)
var_x = sigma_x ** 2
mu_q, logvar_q = 0.3, -0.7 # q(z|x)=N(mu_q, exp(logvar_q))
var_q = math.exp(logvar_q)
log_px = log_norm(x, b, w * w + var_x)
post_var = 1 / (1 + w * w / var_x)
post_mu = post_var * w * (x - b) / var_x
recon = -0.5 * (math.log(2 * math.pi * var_x) + ((x - b - w * mu_q) ** 2 + w * w * var_q) / var_x)
kl_prior = kl_norm(mu_q, var_q, 0, 1)
elbo = recon - kl_prior
gap = log_px - elbo
kl_post = kl_norm(mu_q, var_q, post_mu, post_var)
assert abs(gap - kl_post) < 1e-10
eps = -0.4
def sampled_recon(mu, logvar):
sigma = math.exp(0.5 * logvar)
z = mu + sigma * eps
return log_norm(x, w * z + b, var_x), z, sigma
sample_loglik, z, sigma = sampled_recon(mu_q, logvar_q)
dloglik_dz = (x - (w * z + b)) * w / var_x
path_mu = dloglik_dz
path_logvar = dloglik_dz * 0.5 * sigma * eps
h = 1e-5
fd_mu = (sampled_recon(mu_q + h, logvar_q)[0] - sampled_recon(mu_q - h, logvar_q)[0]) / (2 * h)
fd_logvar = (sampled_recon(mu_q, logvar_q + h)[0] - sampled_recon(mu_q, logvar_q - h)[0]) / (2 * h)
assert abs(path_mu - fd_mu) < 1e-7
assert abs(path_logvar - fd_logvar) < 1e-7
print(round(elbo, 3), round(log_px, 3), round(gap, 3), round(sample_loglik, 3))
For a batched neural VAE, typical shapes are:
x:(B, D)- encoder outputs
mu,logvar:(B, K) - noise
eps:(S, B, K) - latent samples
z = mu[None, :, :] + exp(0.5 * logvar)[None, :, :] * eps:(S, B, K) - decoder log likelihood per sample:
(S, B) - Monte Carlo reconstruction estimate:
(B,) - analytic diagonal-Gaussian KL:
(B,) - per-example ELBO:
(B,) - optimization loss
-elbo.mean(): scalar
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
The demo keeps the latent variable one-dimensional so the hidden inference geometry can be revealed after a prediction. Move the approximate posterior , inspect the prior and likelihood shape, then predict what the ELBO gap will diagnose.
After reveal, compare the target curve and identity values with your prediction. The point is to feel the ELBO as a lower bound whose looseness is measured by the mismatch between and the hidden target distribution.
Live Concept Demo
Explore Variational Autoencoders
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 4/5undergraduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what Variational Autoencoders should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
A latent-variable model trained by maximizing an evidence lower bound; the gap is KL(q_phi(z|x) || p_theta(z|x)), so the encoder is learned inference rather than just compression.
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change Variational Autoencoders should make visible.
Visual Inquiry
Make the image answer a mathematical question
A latent-variable model trained by maximizing an evidence lower bound; the gap is KL(q_phi(z|x) || p_theta(z|x)), so the encoder is learned inference rather than just compression.
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make Variational Autoencoders easier to reason about before the page gives the answer.
Source Grounding
Canonical references for the mechanism on this page.
Introduces the reparameterized VAE objective and the evidence lower bound training view.
Open sourceGrounds stochastic backpropagation for latent-variable generative models with learned inference networks.
Open sourceClaim Review
A latent-variable model trained by maximizing an evidence lower bound; the gap is KL(q_phi(z|x) || p_theta(z|x)), so the encoder is learned inference rather than just compression.
Claims without a substantive review badge still need exact source-support review.
kingma-2013-auto-encoding-variational-bayes, rezende-2014-stochastic-backprop
Use equation, code, and demo objects to check whether the source support is operational.
Kingma/Welling and Rezende/Mohamed/Wierstra both ground VAEs/deep latent-variable models in ELBO optimization with learned inference networks and reparameterized or stochastic backpropagation estimators. Local math now exports the ELBO identity, ELBO decomposition, and reparameterized sample, while the code and demo check the finite ELBO-gap geometry.
Sources: Auto-Encoding Variational Bayes, Stochastic Backpropagation and Approximate Inference in Deep Generative ModelsThe reconstruction term is an expectation under q_phi and often Monte Carlo estimated. Pathwise gradients require a differentiable transform of parameter-independent noise, so this does not cover discrete or non-reparameterizable latents.A bounded review summary is present; still check caveats and exact source scope.Kingma/Welling support q_phi(z|x) as a learned recognition model for the intractable posterior, derive log p_theta(x)=ELBO+KL(q||posterior), decompose the ELBO into E_q log p_theta(x|z)-KL(q||p(z)), and give Gaussian reparameterization. Rezende et al. independently support the recognition-model, lower-bound/free-energy, reconstruction/regularization, and stochastic-backprop structure. Local math, code, and demo now witness the ELBO gap, prior KL, reparameterized sample, and prediction-gated posterior diagnostics.
Reviewer: codex+oracle+codex-5.3; reviewed 2026-05-08Source support candidates
paper 2013Auto-Encoding Variational BayesIntroduces the reparameterized VAE objective and the evidence lower bound training view.
paper 2014Stochastic Backpropagation and Approximate Inference in Deep Generative ModelsGrounds stochastic backpropagation for latent-variable generative models with learned inference networks.
Practice Loop
Try the idea before it explains itself
A latent-variable model trained by maximizing an evidence lower bound; the gap is KL(q_phi(z|x) || p_theta(z|x)), so the encoder is learned inference rather than just compression.
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in Variational Autoencoders.
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptVariational AutoencodersGenerative Models
Code witness comparisonVariational Autoencoders code witness 1assert abs(gap - kl_post) < 1e-10Prediction before revealVariational Autoencoders interactive demoManipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes Variational Autoencoders click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
Variational Autoencoders
Anchored question
What is the smallest example that makes Variational Autoencoders click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:generative-models/vaes.
No local draft saved.
- Source ids to inspect: kingma-2013-auto-encoding-variational-bayes, rezende-2014-stochastic-backprop
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - Variational Autoencoders Object key: concept:generative-models/vaes Context: Generative Models Anchor id: concept/concept-notebook/generative-models/vaes Open question: What is the smallest example that makes Variational Autoencoders click without losing the math? Evidence to inspect: - Source ids to inspect: kingma-2013-auto-encoding-variational-bayes, rezende-2014-stochastic-backprop - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/generative-models/vaes
concept:generative-models/vaes