Bring the mental model from Scaled Dot-Product Attention & Transformer Layers; this page will reuse it instead of restarting from zero.
LLM Systems
LLM Serving at Scale: Prefill, Decode & Continuous Batching
A systems mental model for LLM inference: prefill vs decode, TTFT vs TPOT, batching/scheduling, and why KV cache memory dominates.
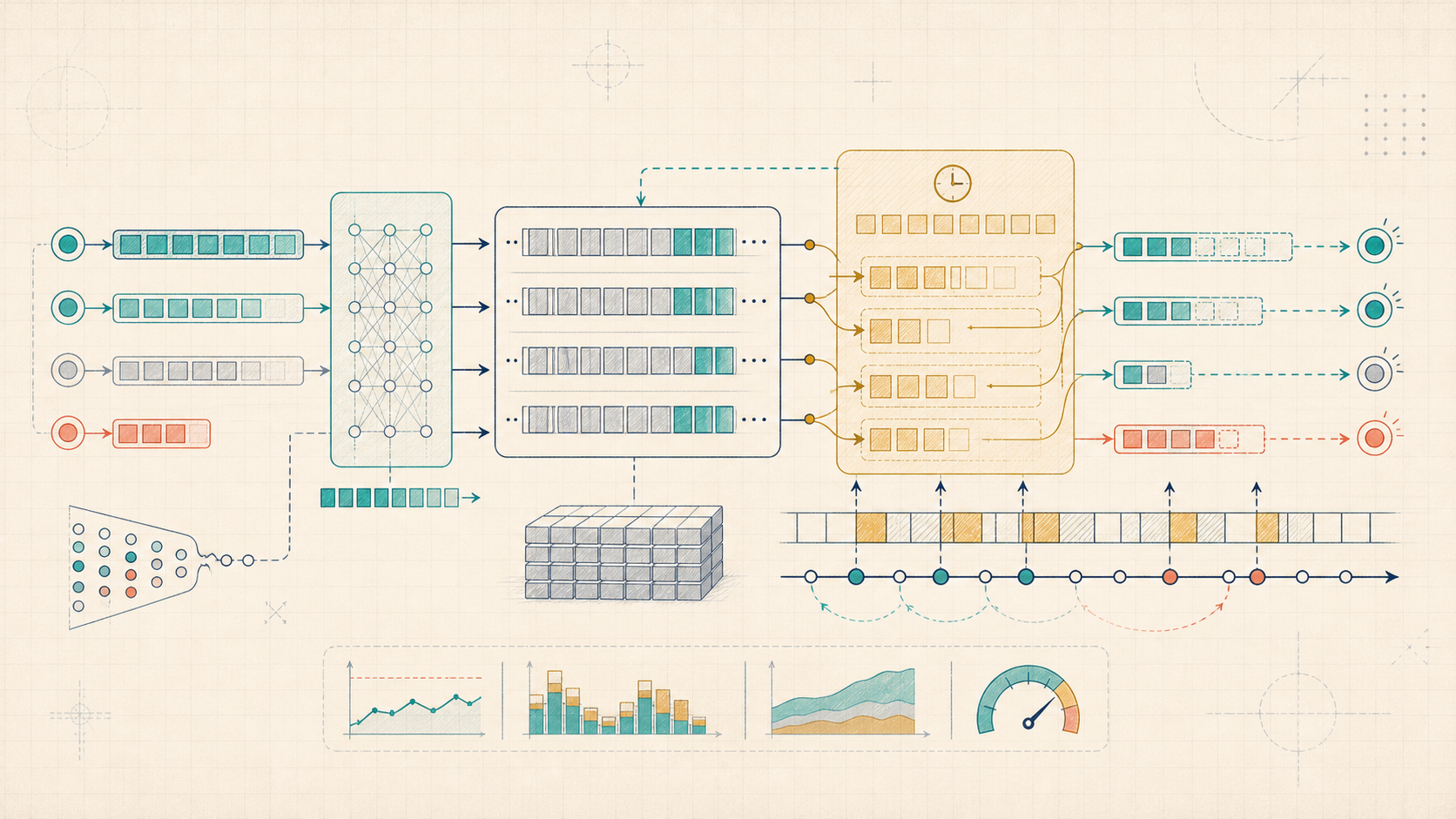
Concept Structure
LLM Serving at Scale: Prefill, Decode & Continuous Batching
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
2prerequisites
2next concepts
2related links
Learning map
LLM Serving at Scale: Prefill, Decode & Continuous BatchingBeforeScaled Dot-Product Attention & Transformer LayersNow4/4 sections readyTryManipulate one control and predict the visible change.NextSpeculative Decoding: Lossless Multi-Token Generation
Conceptual Bridge
What should feel connected as you move through this page.
A systems mental model for LLM inference: prefill vs decode, TTFT vs TPOT, batching/scheduling, and why KV cache memory dominates.
The next edge should feel earned: use the demo prediction here before following Speculative Decoding: Lossless Multi-Token Generation.
Test the linkManipulate one control and predict the visible change.Then continue to Speculative Decoding: Lossless Multi-Token Generation
01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
Serving an LLM is not "run the model once." It's running the model for many users at once, while trying to keep latency low and the GPU busy.
Two phases dominate everything:
- Prefill: process the prompt in parallel (big matrix multiplies, lots of compute).
- Decode: generate one token at a time (small matmuls, but heavy KV cache reads).
This is why a system can feel fast on short prompts but collapse on long context: decode becomes memory-bandwidth bound, and the KV cache becomes the main resource you schedule around.
The practical goal is not raw throughput. It's goodput: how many requests you can serve while meeting latency SLOs.
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Equation 1\text{Latency} \approx \underbrace{\text{TTFT}}_{\text{time to first token}} + (T_{out}-1)\cd...Equation 2\mathrm{Mem}_{KV} \approx B\cdot L\cdot T\cdot H_{kv}\cdot d_{head}\cdot 2 \cdot \mathrm{bytes}.
Latency decomposition (a serving mental model)
Let be the number of generated tokens. A simple but useful decomposition is:
- In this serving mental model, TTFT often tracks prefill.
- TPOT often tracks decode (and KV cache reads).
KV cache memory scaling (why long prompts hurt)
Across a batch of sequences and layers, storing keys and values for tokens costs roughly:
The factor of 2 is for storing both and .
Goodput (a serving SLO mental model)
If you have SLO thresholds , a common objective is:
This captures the reality that "fast on average" is not good enough if tail latency violates SLOs.
Paging / fragmentation waste
If KV memory is allocated in blocks/pages of size (tokens per block), then for a sequence length :
Block-based allocators (PagedAttention-style) make growth predictable and reduce fragmentation under continuous batching.
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
import numpy as np
def kv_gb(T, layers, h_kv, d_head, batch=1, bytes_per_elem=2):
elems = batch * layers * T * h_kv * d_head * 2 # K and V
return elems * bytes_per_elem / 1e9
def waste_tokens(T, P):
return int(np.ceil(T / P) * P - T)
L, Hkv, dh, B = 80, 8, 128, 16 # example: 80 layers, GQA with 8 KV heads, fp16
for T in [2048, 8192, 32768, 131072]:
print("T=", T, "KV~", round(kv_gb(T, L, Hkv, dh, batch=B), 2), "GB")
P = 256 # tokens per page/block
for T in [2000, 8192, 20000]:
print("T=", T, "waste_tokens=", waste_tokens(T, P))
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
Use the demo to explore TTFT vs TPOT tradeoffs, how batching affects goodput, and how repeated KV cache reads shape decode latency in this toy lab.
Live Concept Demo
Explore LLM Serving at Scale: Prefill, Decode & Continuous Batching
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 4/5undergraduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what LLM Serving at Scale: Prefill, Decode & Continuous Batching should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
A systems mental model for LLM inference: prefill vs decode, TTFT vs TPOT, batching/scheduling, and why KV cache memory dominates.
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change LLM Serving at Scale: Prefill, Decode & Continuous Batching should make visible.
Visual Inquiry
Make the image answer a mathematical question
A systems mental model for LLM inference: prefill vs decode, TTFT vs TPOT, batching/scheduling, and why KV cache memory dominates.
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make LLM Serving at Scale: Prefill, Decode & Continuous Batching easier to reason about before the page gives the answer.
Source Grounding
Canonical references for the mechanism on this page.
Primary serving-scheduler source. Orca frames generative transformer inference as multi-iteration autoregressive serving, where each iteration generates one output token, and proposes iteration-level scheduling plus selective batching.
Open sourcePrimary KV-cache serving source. PagedAttention frames high-throughput LLM serving as constrained by huge dynamically growing KV caches, fragmentation, batch-size limits, and paged block allocation.
Open sourceClaim Review
A systems mental model for LLM inference: prefill vs decode, TTFT vs TPOT, batching/scheduling, and why KV cache memory dominates.
Claims without a substantive review badge still need exact source-support review.
yu-2022-orca, kwon-2023-pagedattention
Use equation, code, and demo objects to check whether the source support is operational.
Orca supports the scheduling part: generative Transformer serving is multi-iteration autoregressive inference with one output token per iteration, and fixed request-level batches motivate iteration-level scheduling plus selective batching. PagedAttention supports the memory/throughput part: large dynamic KV caches and fragmentation can limit batch size and throughput. Local math/code/demo are toy witnesses.
Sources: Orca: A Distributed Serving System for Transformer-Based Generative Models, Efficient Memory Management for Large Language Model Serving with PagedAttentionChecks the serving mechanism only. TTFT/TPOT, goodput, KV formula, code, and demo are toy witnesses, not source-derived formulas or production benchmarks. Does not certify vendor latency, scheduler optimality, hardware bottlenecks, throughput gains, or production guarantees.A bounded review summary is present; still check caveats and exact source scope.Checked Orca and PagedAttention: Orca supports autoregressive generative Transformer serving as multi-iteration inference where each iteration emits one token, motivating iteration-level scheduling and selective batching because fixed request-level batches waste capacity. PagedAttention supports KV cache memory as large, dynamic, fragmentation-prone state that can limit batch size and throughput. Local latency/KV math, code, and demo are toy serving witnesses only.
Reviewer: codex+oracle; reviewed 2026-05-07Source support candidates
paper 2022Orca: A Distributed Serving System for Transformer-Based Generative ModelsPrimary serving-scheduler source. Orca frames generative transformer inference as multi-iteration autoregressive serving, where each iteration generates one output token, and proposes iteration-level scheduling plus selective batching.
paper 2023Efficient Memory Management for Large Language Model Serving with PagedAttentionPrimary KV-cache serving source. PagedAttention frames high-throughput LLM serving as constrained by huge dynamically growing KV caches, fragmentation, batch-size limits, and paged block allocation.
Practice Loop
Try the idea before it explains itself
A systems mental model for LLM inference: prefill vs decode, TTFT vs TPOT, batching/scheduling, and why KV cache memory dominates.
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in LLM Serving at Scale: Prefill, Decode & Continuous Batching.
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptLLM Serving at Scale: Prefill, Decode & Continuous BatchingLLM Systems
Code witness comparisonLLM Serving at Scale: Prefill, Decode & Continuous Batching code witness 1elems = batch * layers * T * h_kv * d_head * 2 # K and VPrediction before revealLLM Serving at Scale: Prefill, Decode & Continuous Batching interactive demoManipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes LLM Serving at Scale: Prefill, Decode & Continuous Batching click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
LLM Serving at Scale: Prefill, Decode & Continuous Batching
Anchored question
What is the smallest example that makes LLM Serving at Scale: Prefill, Decode & Continuous Batching click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:llm-systems/llm-serving.
No local draft saved.
- Source ids to inspect: yu-2022-orca, kwon-2023-pagedattention
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - LLM Serving at Scale: Prefill, Decode & Continuous Batching Object key: concept:llm-systems/llm-serving Context: LLM Systems Anchor id: concept/concept-notebook/llm-systems/llm-serving Open question: What is the smallest example that makes LLM Serving at Scale: Prefill, Decode & Continuous Batching click without losing the math? Evidence to inspect: - Source ids to inspect: yu-2022-orca, kwon-2023-pagedattention - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/llm-systems/llm-serving
concept:llm-systems/llm-serving