Bring the mental model from Scaling Laws & Emergent Abilities; this page will reuse it instead of restarting from zero.
Scaling
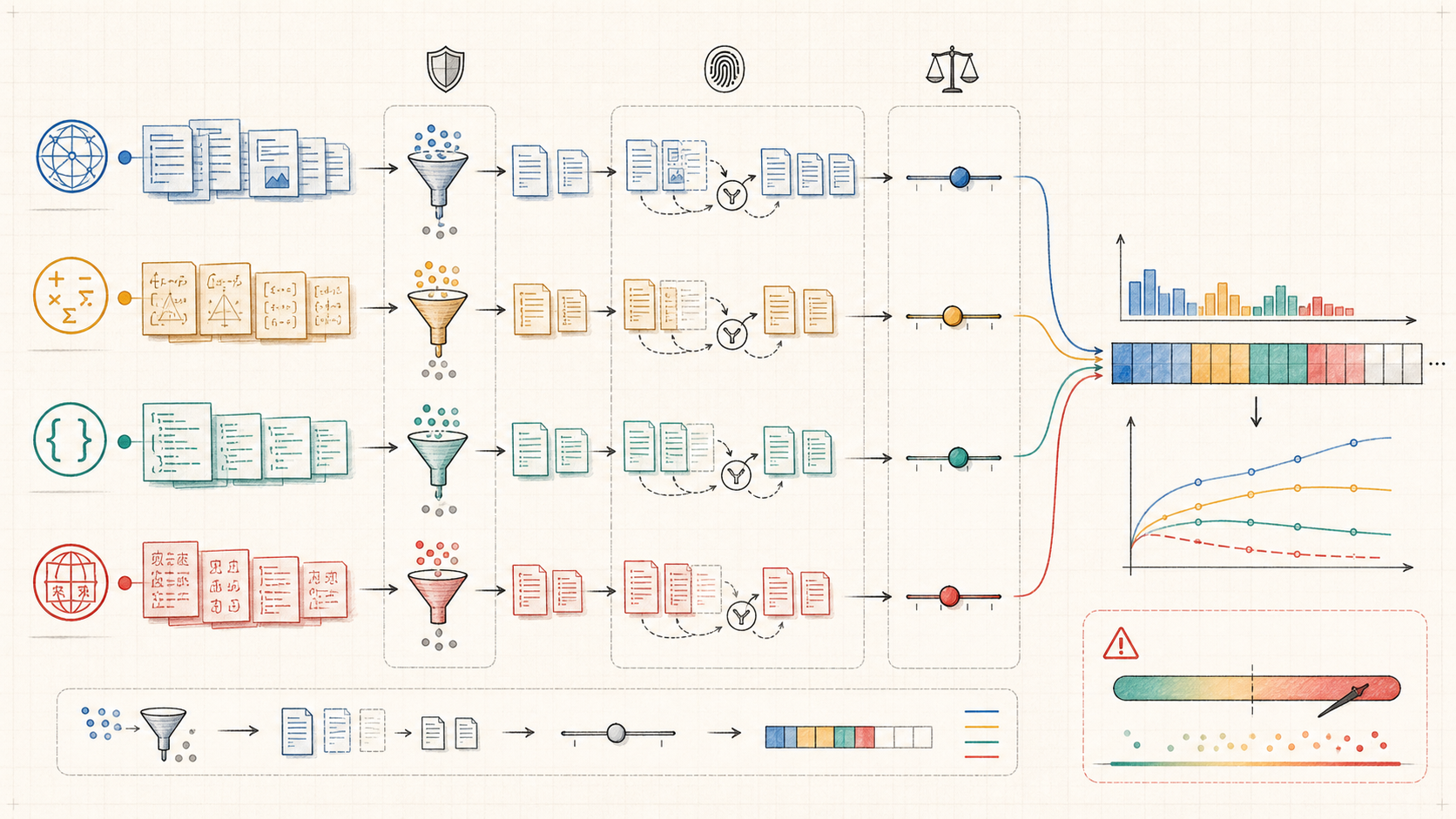
Pretraining Data Mixtures: Designing the Token Distribution
How filtering, deduplication, source weights, and curriculum turn a token budget into an effective pretraining distribution.
Concept Structure
Pretraining Data Mixtures: Designing the Token Distribution
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
3prerequisites
2next concepts
3related links
Learning map
Pretraining Data Mixtures: Designing the Token DistributionBeforeScaling Laws & Emergent AbilitiesNow4/4 sections readyTryManipulate one control and predict the visible change.NextRetrieval-Augmented Generation: External Memory for Generation
Conceptual Bridge
What should feel connected as you move through this page.
How filtering, deduplication, source weights, and curriculum turn a token budget into an effective pretraining distribution.
The next edge should feel earned: use the demo prediction here before following Retrieval-Augmented Generation: External Memory for Generation.
Test the linkManipulate one control and predict the visible change.Then continue to Retrieval-Augmented Generation: External Memory for Generation
01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
Grounding examples: Hoffmann et al., "Training Compute-Optimal Large Language Models", the FineWeb and FineWeb-Edu dataset cards, the Dolma corpus and toolkit, the DCLM / DataComp-LM benchmark, Ye et al., "Data Mixing Laws", and Meta's "The Llama 3 Herd of Models".
Scaling laws teach that model size , training tokens , and compute have to be balanced. But is not a bag of identical units. A token from a deduplicated math solution, a noisy web page, a code file, a translated document, and a benchmark near-duplicate do not train the same distribution.
Pretraining data mixtures make the token budget concrete. Before a model sees a token, raw corpora pass through filters, deduplication, quality classifiers, source weights, and sometimes a late training schedule. Those choices create the effective distribution the optimizer samples from.
FineWeb is a useful public example because it exposes web-data curation as a process rather than a mystery bucket. FineWeb-Edu is useful because its dataset card makes the quality-threshold tradeoff visible: stricter educational filtering can leave far fewer tokens. Dolma and DCLM show the same attitude at system scale: pretraining data is an experimental object, not just a download.
The central question is:
When a run says it trained on tokens, which filtered, deduplicated, weighted, scheduled distribution did those tokens come from?
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Let there be raw sources indexed by , with documents . Here is a document or sequence from a source such as web, code, math, books, multilingual text, or academic text. A tokenizer turns a retained document into next-token examples , where is a context and is the next token.
Now define a retention function , with .
The factors are deliberately plain:
- is a language, safety, format, or heuristic filter.
- is deduplication or near-dedup retention under strictness .
- is a proxy quality or domain score.
- is the score threshold.
For compact notation, is written as a document-level retention factor, though near-dedup decisions can depend on other documents in the retained corpus.
The retained mass is . The curated source distribution is .
For token-position sampling, document-level retention must be length-weighted. Let C_i(c,y) be the retained count or mass of token-position pair (c,y) from source i after filtering and deduplication. For an active source with nonzero retained token mass, define P_i^tok(c,y) = C_i(c,y) / sum_{c',y'} C_i(c',y').
If source had raw token positions, a rough retained-token proxy is .
At training step , choose a source mixture vector , with and .
In practice, weights are normalized over active sources with . If all retained mass is zero, is undefined rather than merely low quality.
The effective token-position distribution is
This is the central object. A pretraining update samples and applies a next-token gradient step on .
If changes late in training, the run is nonstationary. In a deep model, that is not merely the same as averaging all tokens, because optimizer state, learning rate, finite training time, and forgetting can matter.
For a total token budget , define average exposure and expected sampled tokens . A simple repetition-pressure diagnostic is .
If , the run samples source more times than its retained unique-token proxy. Upsampling is sometimes useful, but it is not free.
A toy unique-token approximation, assuming sampling with replacement from retained token positions, is .
Deduplication is a tradeoff: it can reduce memorization, leakage, and repeated boilerplate, but overly strict dedup can also remove useful templates or common domain structure.
For held-out evaluation distributions , define domain losses as L_j(theta_T) = E_{(c,y) in E_j}[-log p_theta_T(y|c)].
A reported validation objective might combine them as with . The weights are a product choice. They are not a law of nature.
Keep contamination separate from token loss. Since near-duplicate checks operate on documents or sequences, define a scheduled document-level mixture and average . For benchmark or evaluation set , a near-duplicate diagnostic can be written as .
The demo's contamination mass is a scalar toy proxy: the average-weighted token share of retained documents flagged as eval-like. Lower validation loss is not automatically better if or the toy proxy rises.
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
This witness is a toy unigram language model. It is faithful to the central mixture-and-loss equations because the learned distribution is exactly the curated mixture distribution, and validation loss is exact cross-entropy under held-out toy distributions. It is not a transformer simulation.
from math import log
from collections import defaultdict
VOCAB = ["story", "fact", "proof", "equation", "def", "loop", "bug", "clickbait"]
DOCS = [
("web_a", "web", 0.65, "w1", False, {"story": 8, "fact": 5, "clickbait": 2}),
("web_b", "web", 0.35, "w2", False, {"story": 7, "clickbait": 7, "fact": 1}),
("web_c", "web", 0.70, "w1", False, {"story": 8, "fact": 5, "clickbait": 2}),
("edu_a", "edu", 0.92, "e1", False, {"proof": 5, "equation": 5, "fact": 3}),
("edu_b", "edu", 0.58, "e2", True, {"proof": 6, "equation": 5, "fact": 1}),
("code_a", "code", 0.86, "c1", False, {"def": 5, "loop": 5, "bug": 1}),
("code_b", "code", 0.40, "c2", False, {"def": 2, "bug": 7, "loop": 1}),
]
EVALS = {
"general": {"story": 0.45, "fact": 0.45, "clickbait": 0.10},
"math": {"proof": 0.45, "equation": 0.45, "fact": 0.10},
"code": {"def": 0.45, "loop": 0.45, "bug": 0.10},
}
def curate(thresholds, dedup=True):
kept, seen = [], set()
for doc_id, src, quality, group, leak, counts in DOCS:
if quality < thresholds.get(src, 0.0):
continue
if dedup and group in seen:
continue
seen.add(group)
kept.append((doc_id, src, quality, group, leak, counts))
return kept
def normalize(counts, eps=1e-9):
total = sum(counts.values()) + eps * len(VOCAB)
return {tok: (counts.get(tok, 0.0) + eps) / total for tok in VOCAB}
def source_stats(kept):
counts_by_src = defaultdict(lambda: defaultdict(float))
tokens_by_src = defaultdict(float)
leaks_by_src = defaultdict(float)
for _, src, _, _, leak, counts in kept:
n = sum(counts.values())
tokens_by_src[src] += n
if leak:
leaks_by_src[src] += n
for tok, n in counts.items():
counts_by_src[src][tok] += n
return counts_by_src, tokens_by_src, leaks_by_src
def normalize_weights(weights, active_sources):
active_sources = list(active_sources)
if not active_sources:
return {}
total = sum(weights.get(src, 0.0) for src in active_sources)
if total <= 0:
return {src: 1.0 / len(active_sources) for src in active_sources}
return {src: weights.get(src, 0.0) / total for src in active_sources}
def mix(source_distributions, weights):
return {
tok: sum(weights.get(src, 0.0) * dist[tok] for src, dist in source_distributions.items())
for tok in VOCAB
}
def evaluate(thresholds, early_mix, late_mix=None, late_fraction=0.0, dedup=True):
kept = curate(thresholds, dedup=dedup)
counts_by_src, tokens_by_src, leaks_by_src = source_stats(kept)
source_distributions = {src: normalize(counts) for src, counts in counts_by_src.items()}
active = list(source_distributions.keys())
w_early = normalize_weights(early_mix, active)
q_early = mix(source_distributions, w_early)
if late_mix and late_fraction > 0:
w_late = normalize_weights(late_mix, active)
q_late = mix(source_distributions, w_late)
q = {tok: (1 - late_fraction) * q_early[tok] + late_fraction * q_late[tok] for tok in VOCAB}
avg_w = {src: (1 - late_fraction) * w_early.get(src, 0.0) + late_fraction * w_late.get(src, 0.0) for src in active}
else:
q = q_early
avg_w = w_early
losses = {
name: -sum(p * log(max(q.get(tok, 0.0), 1e-12)) for tok, p in p_eval.items())
for name, p_eval in EVALS.items()
}
contamination = sum(avg_w[src] * leaks_by_src[src] / tokens_by_src[src] for src in active)
repetition = {src: 180 * avg_w[src] / tokens_by_src[src] for src in active}
return {
"kept_docs": [doc[0] for doc in kept],
"losses": {k: round(v, 3) for k, v in losses.items()},
"contamination_mass": round(contamination, 3),
"repetition_pressure": {k: round(v, 2) for k, v in repetition.items()},
}
baseline = evaluate(
thresholds={"web": 0.0, "edu": 0.0, "code": 0.0},
early_mix={"web": 0.70, "edu": 0.15, "code": 0.15},
dedup=False,
)
curated_late = evaluate(
thresholds={"web": 0.55, "edu": 0.60, "code": 0.60},
early_mix={"web": 0.50, "edu": 0.25, "code": 0.25},
late_mix={"web": 0.35, "edu": 0.35, "code": 0.30},
late_fraction=0.20,
dedup=True,
)
print("baseline:", baseline)
print("curated + late:", curated_late)
assert curated_late["losses"]["math"] < baseline["losses"]["math"]
assert curated_late["losses"]["code"] < baseline["losses"]["code"]
assert curated_late["losses"]["general"] > baseline["losses"]["general"]
assert curated_late["contamination_mass"] < baseline["contamination_mass"]
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
Use the Effective Token Distribution Explorer to change mixture weights, filter threshold, deduplication, and a late math/code anneal. Watch three quantities separately:
- validation losses for general, math, and code toy distributions,
- repetition pressure and retained token mass by source,
- leakage and diversity diagnostics.
The demo uses a tiny embedded corpus. It is a toy unigram/proxy-loss model, not predicted LLM performance. In the toy, late annealing changes the time-averaged unigram distribution used for proxy loss; it does not show optimizer-state, learning-rate, forgetting, or ordering effects that make real curricula nontrivial. Its job is to make the object and its time average visible.
Live Concept Demo
Explore Pretraining Data Mixtures: Designing the Token Distribution
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 4/5undergraduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what Pretraining Data Mixtures: Designing the Token Distribution should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
How filtering, deduplication, source weights, and curriculum turn a token budget into an effective pretraining distribution.
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change Pretraining Data Mixtures: Designing the Token Distribution should make visible.
Visual Inquiry
Make the image answer a mathematical question
How filtering, deduplication, source weights, and curriculum turn a token budget into an effective pretraining distribution.
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make Pretraining Data Mixtures: Designing the Token Distribution easier to reason about before the page gives the answer.
Claim Review
How filtering, deduplication, source weights, and curriculum turn a token budget into an effective pretraining distribution.
Source IDs and witness objects are attached for review; they are not proof by themselves.
Add source metadata before claiming support.
Use equation, code, and demo objects to check whether the source support is operational.
Source support candidates
No structured source note is attached yet.
Practice Loop
Try the idea before it explains itself
How filtering, deduplication, source weights, and curriculum turn a token budget into an effective pretraining distribution.
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in Pretraining Data Mixtures: Designing the Token Distribution.
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptPretraining Data Mixtures: Designing the Token DistributionScaling
Code witness comparisonPretraining Data Mixtures: Designing the Token Distribution code witness 1assert curated_late["losses"]["math"] < baseline["losses"]["math"]Prediction before revealPretraining Data Mixtures: Designing the Token Distribution interactive demoManipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes Pretraining Data Mixtures: Designing the Token Distribution click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
Pretraining Data Mixtures: Designing the Token Distribution
Anchored question
What is the smallest example that makes Pretraining Data Mixtures: Designing the Token Distribution click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:scaling/pretraining-data-mixtures.
No local draft saved.
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - Pretraining Data Mixtures: Designing the Token Distribution Object key: concept:scaling/pretraining-data-mixtures Context: Scaling Anchor id: concept/concept-notebook/scaling/pretraining-data-mixtures Open question: What is the smallest example that makes Pretraining Data Mixtures: Designing the Token Distribution click without losing the math? Evidence to inspect: - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/scaling/pretraining-data-mixtures
concept:scaling/pretraining-data-mixtures