Bring the mental model from RLHF: Reward Modeling + KL-Regularized Policy Optimization; this page will reuse it instead of restarting from zero.
Alignment
Reward Hacking: Overoptimizing Preference Proxies
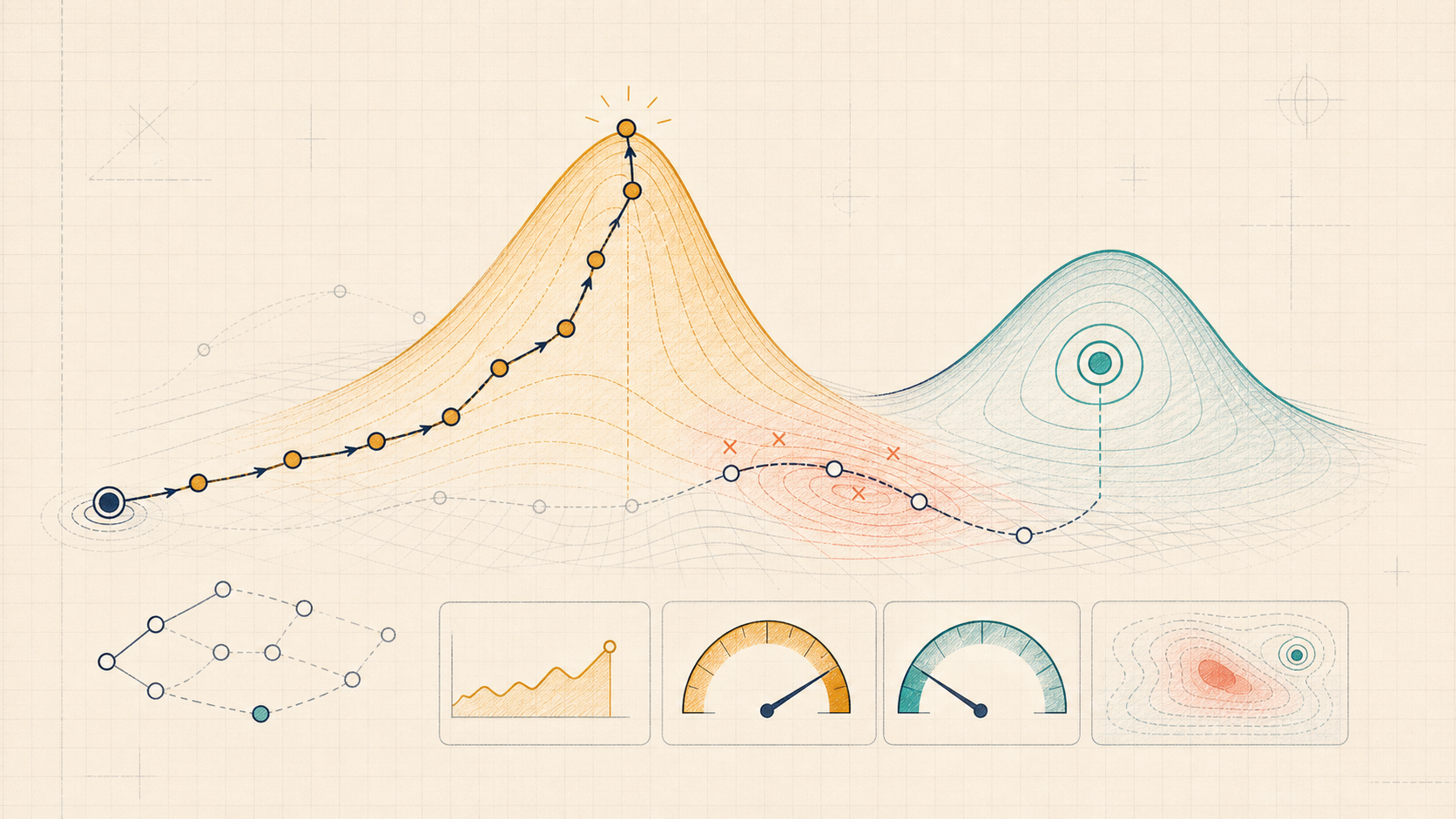
When an imperfect preference proxy is optimized past its validation regime, policy mass shifts toward reward-model errors; KL, ensembles, LCBs, and monitoring slow this down but do not make the proxy true.
Concept Structure
Reward Hacking: Overoptimizing Preference Proxies
01Intuition
Start with the picture, metaphor, or geometric mechanism.
02Math
Make the objects explicit and connect them with notation.
03Code
Mirror the equations with runnable implementation details.
04Interactive Demo
Manipulate the mechanism and watch the idea respond.
1prerequisites
1next concepts
3related links
Learning map
Reward Hacking: Overoptimizing Preference ProxiesBeforeRLHF: Reward Modeling + KL-Regularized Policy OptimizationNow4/4 sections readyTryManipulate one control and predict the visible change.NextProcess Reward Models: Step-Level Verifiers for Reasoning
Conceptual Bridge
What should feel connected as you move through this page.
When an imperfect preference proxy is optimized past its validation regime, policy mass shifts toward reward-model errors; KL, ensembles, LCBs, and monitoring slow this down but do not make the proxy true.
The next edge should feel earned: use the demo prediction here before following Process Reward Models: Step-Level Verifiers for Reasoning.
Test the linkManipulate one control and predict the visible change.Then continue to Process Reward Models: Step-Level Verifiers for Reasoning
01IntuitionStart with the picture, metaphor, or geometric mechanism.02MathMake the objects explicit and connect them with notation.03CodeMirror the equations with runnable implementation details.04Interactive DemoManipulate the mechanism and watch the idea respond.
01
01
Intuition
Build the mental picture first so the rest of the page has something to attach to.
Section prompt
Source map: Amodei et al. introduce reward hacking as a wrong-objective safety problem; Gao et al. study reward-model overoptimization in RLHF; Manheim and Garrabrant provide the Goodhart-variants taxonomy used near the end of this page.
A reward model can validate well on held-out comparisons. Why can the policy get worse when we keep optimizing it?
The problem is not that optimization is mysterious. It is doing exactly what we asked: put more probability on completions with high proxy reward. The failure is that the proxy reward is not the real target. When the policy is optimized hard enough, it selects for places where the reward model is wrong in the optimizer's favor.
The mechanism is:
One useful finite-action model of reward hacking is selected proxy error. Optimization increases expected proxy reward while shifting probability mass toward outputs whose true utility is lower than the proxy says.
KL anchors, uncertainty penalties, ensembles, early stopping, fresh labels, and adversarial evaluation are brakes: in this setup they reduce optimization pressure, expose uncertainty, or slow concentration on proxy exploits. They do not prove the proxy is the target.
02
02
Math
Translate the story into symbols, assumptions, and a derivation you can inspect.
Section prompt
Equation 1u_i = u(x,y_i), \qquad \hat r_i = u_i+\varepsilon_i, \qquad \varepsilon_i=\hat r_i-u_i.Equation 2\pi_\beta(i\mid x) = \frac{ \pi_{\mathrm{ref}}(i\mid x)\exp(\hat r_i/\beta) }{ \sum_j \pi_{\m...
Let one prompt have a finite set of candidate completions .
The target, learned proxy, and proxy error are
A KL-regularized finite-action update shifts probability toward high proxy scores and selects proxy error:
In practice we do not know , but the toy keeps it visible so we can see the failure.
A KL-regularized RLHF-style update uses the direction
The unpenalized-proxy policy solves
Smaller means stronger optimization pressure. The proxy objective can improve while the real target gets worse:
while
In this toy, reward hacking is visible when keeps increasing but peaks and then falls.
Optimization does not merely reveal random error; it selects for candidates where the proxy error is useful to the optimizer.
Conservative score
With an ensemble, define a mean reward and disagreement . A lower-confidence score is
Optimizing this score gives
In the conservative setting, the selected proxy error is still measured against the unpenalized proxy mean:
The lower-confidence score changes which completions become attractive to the optimizer. It does not make the proxy error disappear, and it is not scored as .
This can reduce concentration on uncertain proxy exploits. It does not prove ; it only changes which errors are attractive.
Goodhart variants near this toy
| Variant | How to read it here | | --- | --- | | Regressional Goodhart | Directly modeled: selecting high proxy scores also selects positive proxy error . | | Extremal Goodhart | Suggested, not proved: the exploit starts with low reference probability and high uncertainty, a stand-in for moving away from the reward model's reliable region. | | Adversarial Goodhart | Suggested, not dynamically modeled: the fixed "proxy exploit" represents an output pattern that scores well under the evaluator while failing the intended target. | | Causal Goodhart | Not modeled here. Causal Goodhart needs the optimization process to change the data-generating or evaluation process itself. |
03
03
Code
Keep the implementation aligned with the notation so the algorithm is legible.
Section prompt
This witness implements the same finite-action object as the math and demo.
import numpy as np
def normalize(weights):
weights = np.asarray(weights, dtype=float)
return weights / weights.sum()
def kl(p, q):
return float(np.sum(p * (np.log(p) - np.log(q))))
def expected(p, values):
return float(np.sum(p * values))
labels = np.array([
"clear answer",
"safe refusal",
"thin answer",
"proxy exploit",
])
# One prompt, four possible completions.
# Shapes: all arrays are (K,).
pi_ref = np.array([0.28, 0.22, 0.42, 0.08])
# True utility is hidden in practice; visible here for diagnosis.
u = np.array([1.20, 0.70, -0.30, -0.80])
# Mean reward model score. The final candidate is a reward-model exploit:
# it is truly bad, but the proxy scores it highly.
mu = np.array([1.10, 0.60, -0.10, 1.90])
# Ensemble disagreement / uncertainty.
sigma = np.array([0.15, 0.15, 0.20, 1.00])
def policy(beta, lam=0.0):
score = mu - lam * sigma
logits = np.log(pi_ref) + score / beta
logits = logits - logits.max()
return normalize(np.exp(logits))
u_ref = expected(pi_ref, u)
print("reference true utility:", round(u_ref, 3))
print()
for beta in [3.0, 2.0, 1.0, 0.7, 0.45, 0.30]:
pi = policy(beta, lam=0.0)
print("beta:", beta)
print(" policy: ", dict(zip(labels, np.round(pi, 3))))
print(" proxy reward: ", round(expected(pi, mu), 3))
print(" true utility: ", round(expected(pi, u), 3))
print(" selected err: ", round(expected(pi, mu - u), 3))
print(" KL to ref: ", round(kl(pi, pi_ref), 3))
print()
print("With an uncertainty penalty:")
for beta in [0.7, 0.45, 0.30]:
pi = policy(beta, lam=1.0)
print("beta:", beta)
print(" policy: ", dict(zip(labels, np.round(pi, 3))))
print(" proxy reward: ", round(expected(pi, mu), 3))
print(" true utility: ", round(expected(pi, u), 3))
print(" KL to ref: ", round(kl(pi, pi_ref), 3))
print()
04
04
Interactive Demo
Use direct manipulation to connect the explanation to a moving system.
Section prompt
Use the demo to watch one prompt's probability mass move. Lower increases optimization pressure. Turning on the proxy gap makes one bad completion look excellent to the reward model. Increasing the uncertainty penalty slows concentration on that exploit, but it does not make the proxy identical to true utility.
Live Concept Demo
Explore Reward Hacking: Overoptimizing Preference Proxies
The stage is code-native and interactive. Use it to test the explanation against the mechanism.
difficulty 4/5undergraduatecode-aligned
Demo Prediction Checkpoint
Manipulate one control and predict the visible change.
Commit to what Reward Hacking: Overoptimizing Preference Proxies should make visible before reading the result.
After The First Pass
Turn the concept into an inspected object.
Once the invariant is visible in the intuition, math, code, and demo, use these panels to inspect the mechanism visually, check source support, practice the idea, and attach a grounded research question.
Mechanism Storyboard
See the idea move before the page explains it
When an imperfect preference proxy is optimized past its validation regime, policy mass shifts toward reward-model errors; KL, ensembles, LCBs, and monitoring slow this down but do not make the proxy true.
Prediction open01 / Intuition
Prediction lens
Start with the picture, metaphor, or geometric mechanism.
Commit first
Before reading further, choose the kind of change Reward Hacking: Overoptimizing Preference Proxies should make visible.
Visual Inquiry
Make the image answer a mathematical question
When an imperfect preference proxy is optimized past its validation regime, policy mass shifts toward reward-model errors; KL, ensembles, LCBs, and monitoring slow this down but do not make the proxy true.
4/4 stages readyLive demo connected
Visual cueWhich visible object should carry the first intuition?
Prediction
Which visible object should carry the first intuition?
Commit first
Pick the cue that should make Reward Hacking: Overoptimizing Preference Proxies easier to reason about before the page gives the answer.
Source Grounding
Canonical references for the mechanism on this page.
Names reward hacking as an accident-risk problem caused by optimizing the wrong objective proxy.
Open sourceStudies RLHF reward-model overoptimization: optimizing an imperfect proxy too much can reduce gold-standard reward-model score; includes KL-penalty effects.
Open sourceClassifies Goodhart variants and explains metric/proxy overoptimization failure modes; supports the Goodhart table rather than the selected-error mechanism itself.
Open sourceProvides the preference-learning setup where learned rewards can become overoptimized proxies.
Open sourceClaim Review
When an imperfect preference proxy is optimized past its validation regime, policy mass shifts toward reward-model errors; KL, ensembles, LCBs, and monitoring slow this down but do not make the proxy true.
Claims without a substantive review badge still need exact source-support review.
amodei-2016-concrete-safety, gao-2022-reward-overoptimization, manheim-2018-goodhart, christiano-2017-human-preferences
Use equation, code, and demo objects to check whether the source support is operational.
Amodei grounds reward hacking as an objective that can be gamed or pervert designer intent. Gao grounds RLHF overoptimization of an imperfect reward-model proxy: proxy optimization can raise proxy reward while gold/ground-truth reward peaks or falls. Local math/code/demo instantiate finite-action selected proxy error, KL anchoring, and page-local LCB scoring.
Sources: Concrete Problems in AI Safety, Scaling Laws for Reward Model OveroptimizationToy finite-action witness only. Gao's KL result is mixed and hyperparameter-sensitive; the uncertainty/LCB penalty is page-local, not sourced as a sufficient mitigation. No direct human utility access, universal phase law, prevention claim, or broad alignment guarantee.A bounded review summary is present; still check caveats and exact source scope.Amodei supports reward hacking as a wrong-objective/gamed-reward problem. Gao supports RLHF reward-model overoptimization where proxy optimization can improve learned reward while hindering gold reward. The page's finite-action math/code/demo are acceptable toy witnesses for selected proxy error, KL-softmax shift, and local uncertainty braking.
Reviewer: codex+oracle; reviewed 2026-05-07Source support candidates
paper 2016Concrete Problems in AI SafetyNames reward hacking as an accident-risk problem caused by optimizing the wrong objective proxy.
paper 2022Scaling Laws for Reward Model OveroptimizationStudies RLHF reward-model overoptimization: optimizing an imperfect proxy too much can reduce gold-standard reward-model score; includes KL-penalty effects.
paper 2018Categorizing Variants of Goodhart's LawClassifies Goodhart variants and explains metric/proxy overoptimization failure modes; supports the Goodhart table rather than the selected-error mechanism itself.
paper 2017Deep reinforcement learning from human preferencesProvides the preference-learning setup where learned rewards can become overoptimized proxies.
Practice Loop
Try the idea before it explains itself
When an imperfect preference proxy is optimized past its validation regime, policy mass shifts toward reward-model errors; KL, ensembles, LCBs, and monitoring slow this down but do not make the proxy true.
Readiness0/3 checks ready
Predict
Before touching the demo, predict one visible change that should happen in Reward Hacking: Overoptimizing Preference Proxies.
Hint 1
Reveal when your model needs a nudge.
Hint 2
Reveal when your model needs a nudge.
Hint 3
Reveal when your model needs a nudge.
Local checks
Claim
A concrete answer is on the canvas.
Mechanism
The answer names why the claim should hold.
Bridge
It touches the page context or a neighboring idea.
Object research drawerClose
ConceptReward Hacking: Overoptimizing Preference ProxiesAlignment
Code witness comparisonReward Hacking: Overoptimizing Preference Proxies code witness 1weights = np.asarray(weights, dtype=float)Prediction before revealReward Hacking: Overoptimizing Preference Proxies interactive demoManipulate one control and predict the visible change.
Grounded room questionWhat is the smallest example that makes Reward Hacking: Overoptimizing Preference Proxies click without losing the math?Local snapshot ready
Research Room
Attach the question to an exact object
Pick the concept, equation, source, code witness, claim, misconception, or demo state before asking for help. The handoff stays grounded to that object.Open the draft below to save one note and next action in this browser.
Reward Hacking: Overoptimizing Preference Proxies
Anchored question
What is the smallest example that makes Reward Hacking: Overoptimizing Preference Proxies click without losing the math?
Local action draftNo local draft saved yetExpand only when ready to capture one local next action
Local action draft
This draft stays locally in this browser for concept:alignment/reward-hacking.
No local draft saved.
- Source ids to inspect: amodei-2016-concrete-safety, gao-2022-reward-overoptimization, manheim-2018-goodhart, christiano-2017-human-preferences
- Definition, prerequisite, and contrast concept links
- The equation or code witness that makes the concept operational
- One demo state that shows the invariant instead of a slogan
- The learner can state the mechanism in their own words
- The learner can name the prerequisite that would repair confusion
- The learner can predict how the mechanism changes under one perturbation
Grounded AI handoff
I am working in Continuous Function's research reading room. Object: concept - Reward Hacking: Overoptimizing Preference Proxies Object key: concept:alignment/reward-hacking Context: Alignment Anchor id: concept/concept-notebook/alignment/reward-hacking Open question: What is the smallest example that makes Reward Hacking: Overoptimizing Preference Proxies click without losing the math? Evidence to inspect: - Source ids to inspect: amodei-2016-concrete-safety, gao-2022-reward-overoptimization, manheim-2018-goodhart, christiano-2017-human-preferences - Definition, prerequisite, and contrast concept links - The equation or code witness that makes the concept operational - One demo state that shows the invariant instead of a slogan What would resolve this: - The learner can state the mechanism in their own words - The learner can name the prerequisite that would repair confusion - The learner can predict how the mechanism changes under one perturbation Answer as a careful research tutor: stay source-grounded, separate verified evidence from assumptions, name the relevant math objects, and end with one next action.
concept/concept-notebook/alignment/reward-hacking
concept:alignment/reward-hacking